摘要
本课题面向断纸故障标记数据短缺而生产工况切换较多,故障诊断建模复用困难的问题,提出了分别基于参数和特征的断纸故障迁移模型建模方法,通过分析定量设定值及其强相关变量的数据分布特征,对工业数据进行了基础工况划分,并以马氏距离、多核最大均值差异等距离函数评估验证了工况划分的可靠性。在所划分的工况数据基础上,将依据有效断纸故障数据较多的工况建立的断纸故障模型迁移至数据缺失的工况中。结果表明,建立的故障诊断迁移模型在不同的工况迁移任务中分别达到了98.3%、94.6%、96.4%的诊断准确率,提高了模型的泛用性,促进其面向不同的造纸生产过程进行更广泛和更精确的故障诊断。
纸是人们日常生活中不可或缺的必需
故障诊断是流程工业和过程系统工程领域中的一个重要研究方向,涉及对系统、设备或过程的监测和分析,及时发现异常情况并进行维护或优化。随着技术的发展,故障诊断已经从传统的基于经验的方法转变为基于工业互联网和“大数据
迁移学习可实现减少对大量标记数据训练机器学习诊断模型的依赖,从而推动所建立的故障诊断方法更广泛地应用于现实的工业工程场景
基于上述研究背景和现状,本课题提出一种基于迁移学习的生活用纸造纸过程多工况故障诊断模型。根据关键过程参数,将实际生产过程细分为不同的生产工况,将机理分析与数据分析相结合,针对数据较为全面的常用工况构建诊断模型,并在诊断模型的基础上引入迁移学习方法,对模型进行面向多个目标域工况的更新泛化,提高模型的泛用性,使其可以应用于更多的生产过程与实际应用场景。
通过采集某生活用纸厂的实际生产运行数据,对生活用纸断纸故障进行综合分析;对数据中存在缺失、异常值等问题,利用皮尔森相关系数法和归一化法对其进行清洗,以纸机运行数据中断纸信号来判断纸机运行状态,断纸信号同时包括了计划停机信号和故障断纸信号;筛选出如换刀、停机设备清洗等场景下的人为停机数据。
考虑到多工况数据差异较大的情况,对造纸机运行关键过程参数进行了分析,根据生产过程的定量设定值变化对不同的生产过程进行了划分,并根据其他关键过程变量对同类工况进行了合
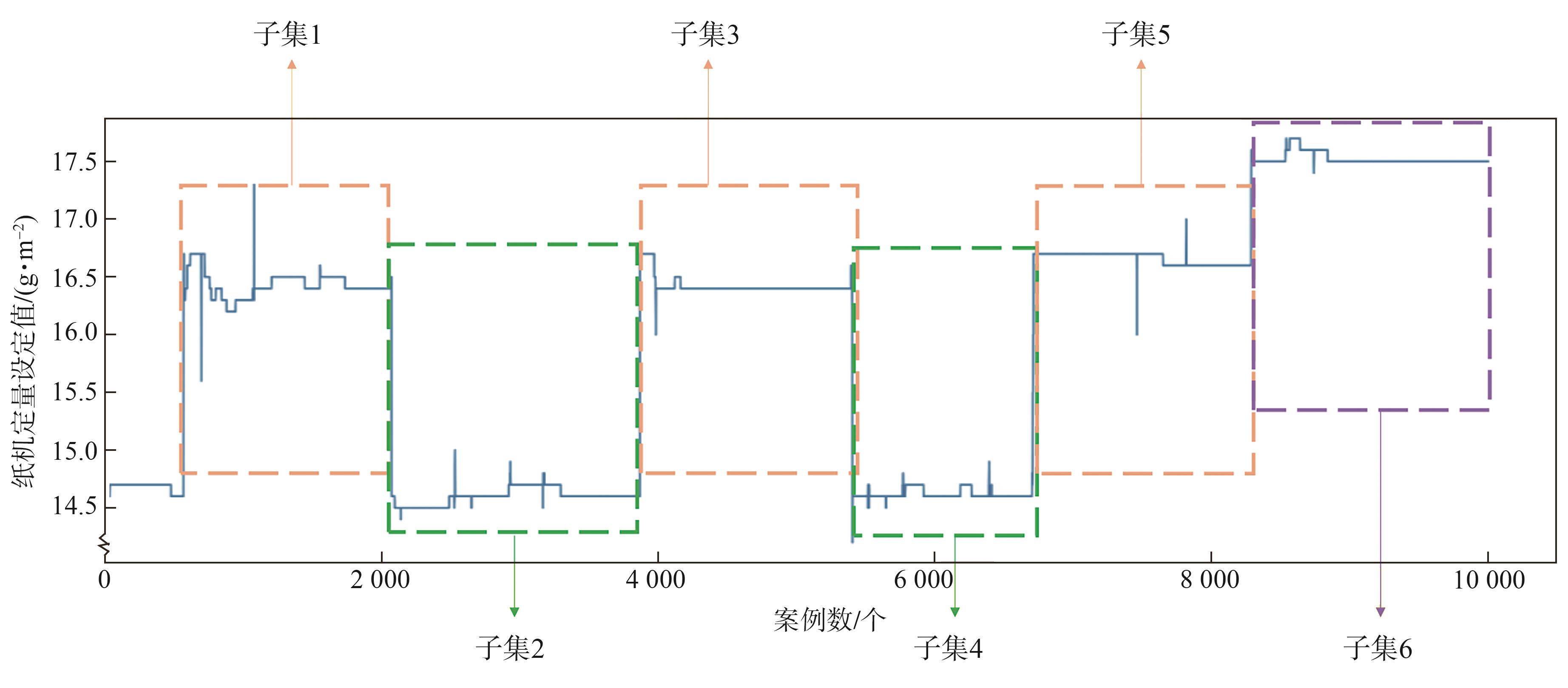
图1 工况子集切分示意图
Fig. 1 Diagram of working condition subset segmentation
根据纸机定量设定值的变化,对采集到的数据集进行切分,得到3种不同工况共6个不同时序数据子集,并就定量与对生产过程的影响较强的变量之间的相关性进行分析。
通过对工况数据进行初步切分后,本课题根据上缸定量、纸机车速、长纤占比、上浆流量等与工况相关性强的参数变量对相近的样本集进行了聚合。为便于观察,数据集按照纸机定量设置值的范围区间进行重新排列,其多样本集的不同参数变量数据分布如
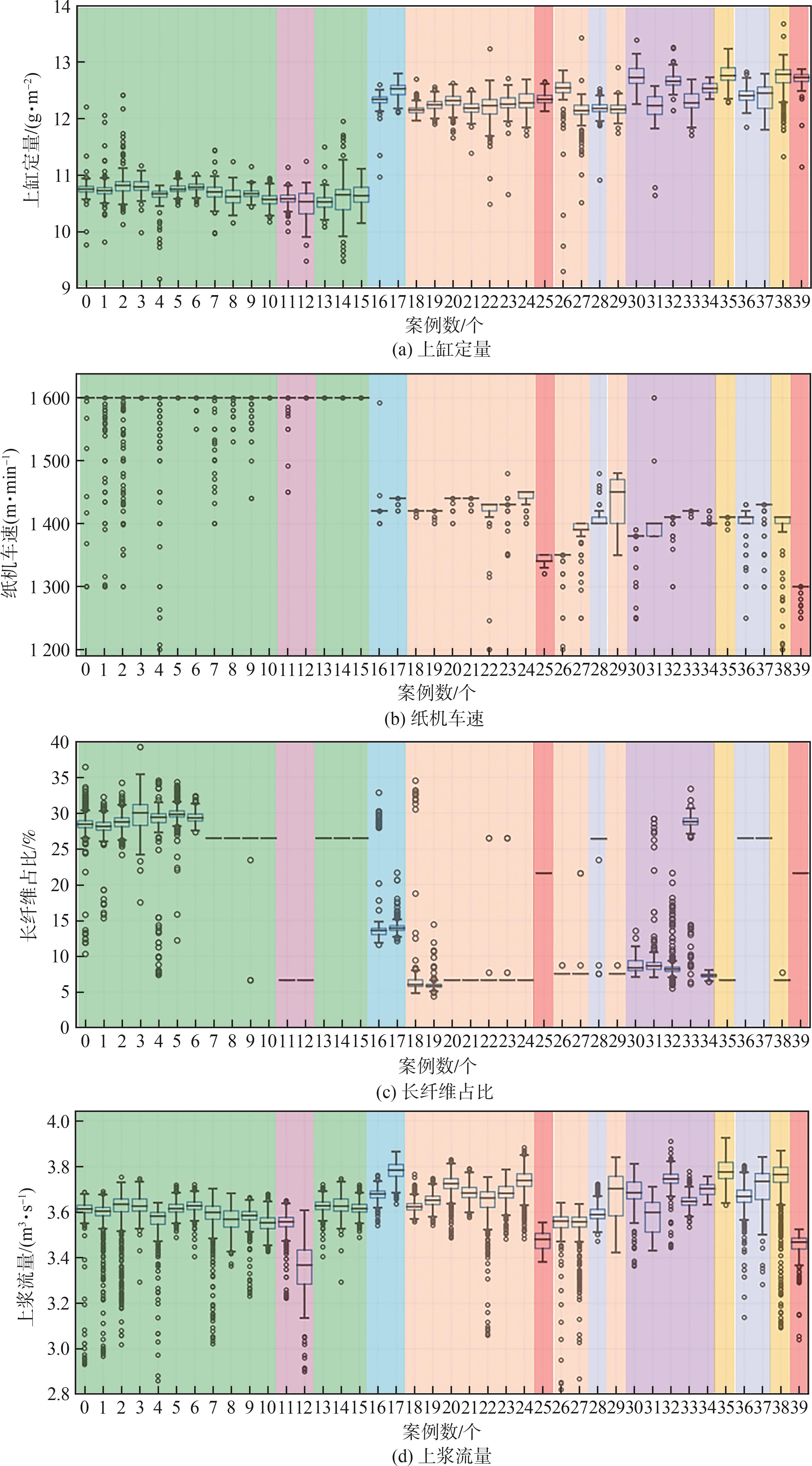
图2 基于定量设定值相关性较高的上缸定量、纸机车速、长纤维占比、上浆流量分布箱线图分析得出的工况划分示意图
Fig. 2 Diagram of working condition division based on boxplot of weight, paper machine speed, long fiber proportion, and sizing flow distribution
在生产过程中,纸机定量设定值与纸机车速关系密切。从
对现有的数据集进行拆分与重组,并最终得到如
本课题基于前期研
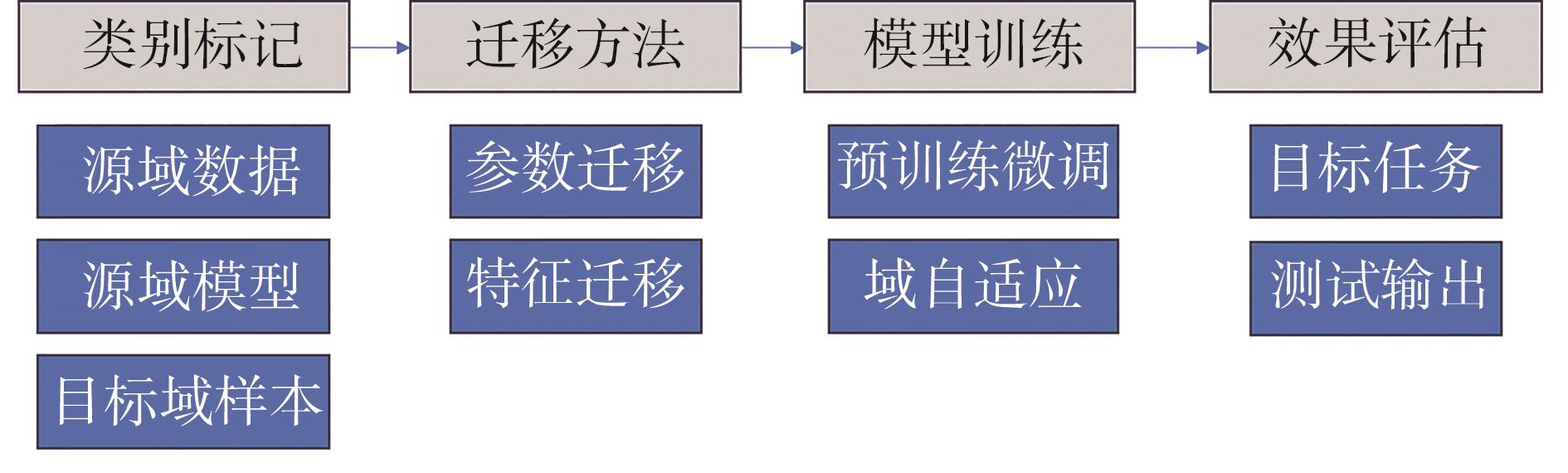
图3 迁移故障诊断流程
Fig. 3 Flowchart of transfer learning fault diagnosis
为实现在不同工况下的纸机断纸故障诊断,本节建立的参数迁移模型整体框架包含特征提取层和故障分类层,其中模型的特征提取模块的参数由源域数据训练得到,将得到的参数和权重进行冻结,并采用目标域中的样本对分类层结构参数进行微调后,将模型用于目标工况的故障诊断,其模型结构如
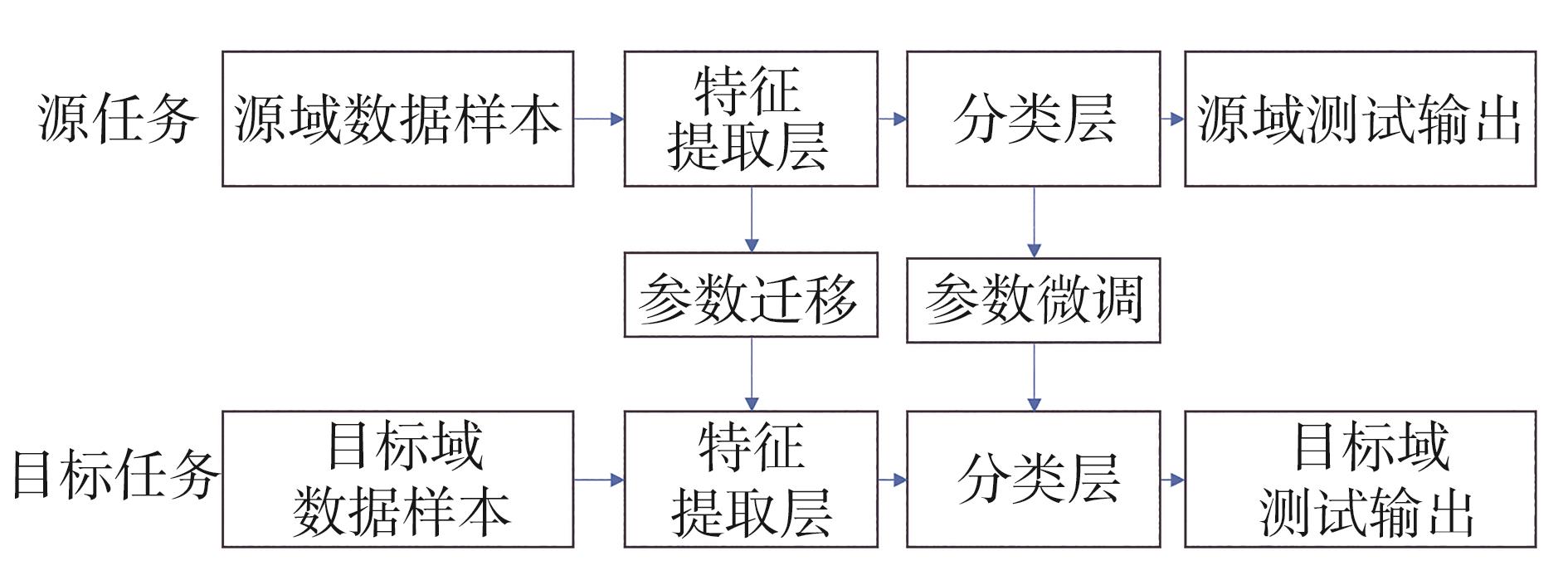
图4 参数迁移过程示意图
Fig. 4 Schematic diagram of the parameter transfer process
参数迁移将在源任务上训练好的模型参数应用到另一个任务上,加速目标任务的学习过程,提高模型的性能。参数迁移将预训练模型的特征提取层的一部分用于目标任务的特征提取,冻结这部分的参数使其不参与迭代更新;微调是在预训练模型的基础上,继续训练模型,使模型在目标任务中有更佳的表现。微调过程一般仅需要较少的样本。虽然不同工况下纸机的工艺参数设定有所不同,但基于同纸机设备的运行数据的参数与数据特征会存在一定的相似
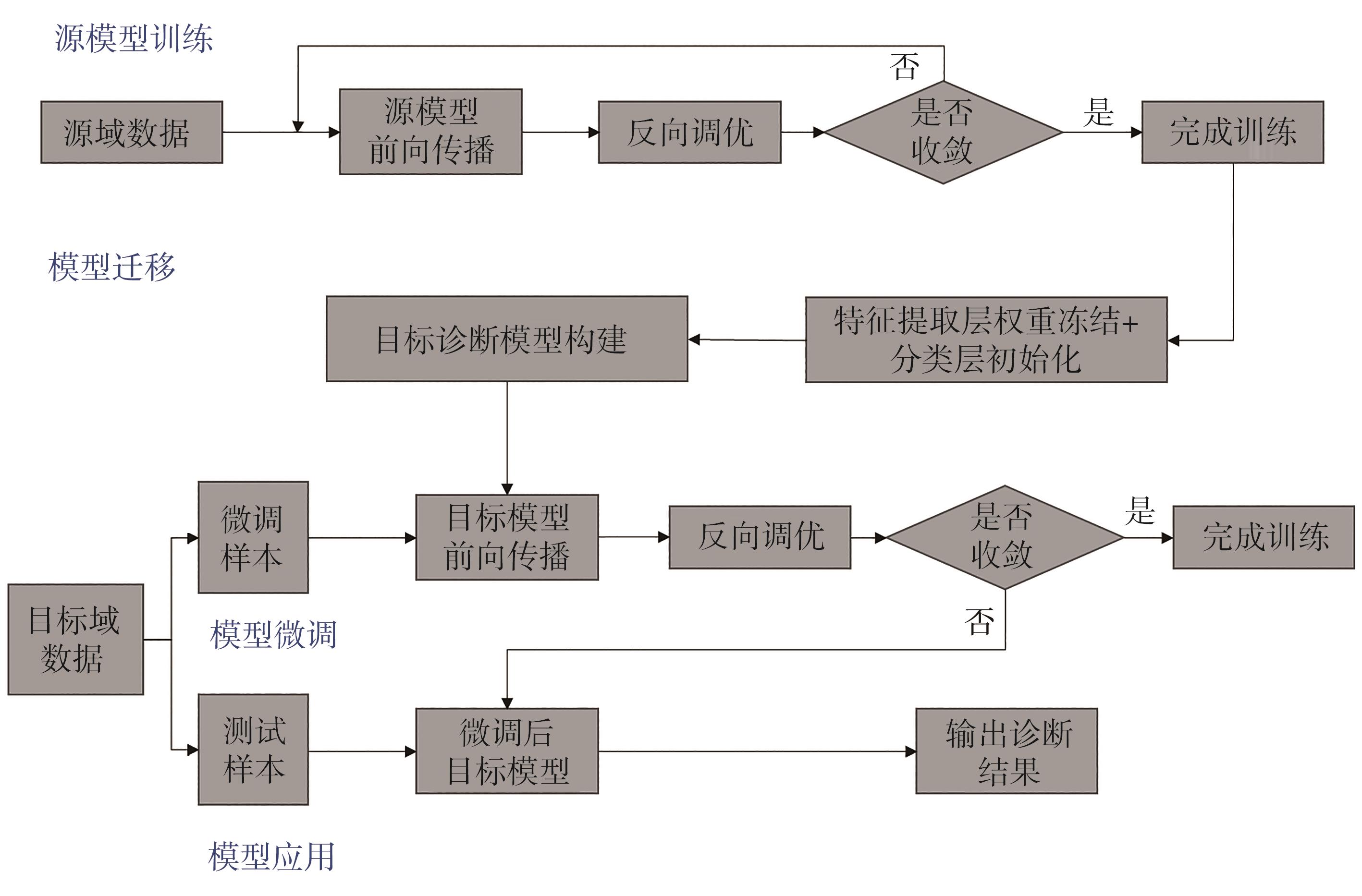
图5 参数迁移故障诊断流程图
Fig. 5 Flowchart of parameter transfer fault diagnosis
在源模型训练阶段,将工况A的纸机运行监测数据及断纸故障标记数据作为源域数据并训练,目标工况B和工况C的数据则作为目标域数据,划出小部分作为微调样本,其余数据用于模型测试。在模型迁移阶段,将源网络的特征提取模块的参数权重迁移到目标网络模型中,用以提取目标域的参数特征信息,并将初始化后的目标模型的分类层应用于故障分类,构建参数迁移故障诊断模型。在模型微调阶段,对于目标域模型,冻结其特征提取层,并利用微调样本分类层进行参数微调。最后,对模型应用效果进行验证,利用微调后的目标模型对目标域的测试样本进行诊断,评估迁移故障诊断模型效果。
基于特征的迁移方法在最小化源域和目标域之间的特征分布差异,更新网络参数学习域不变特
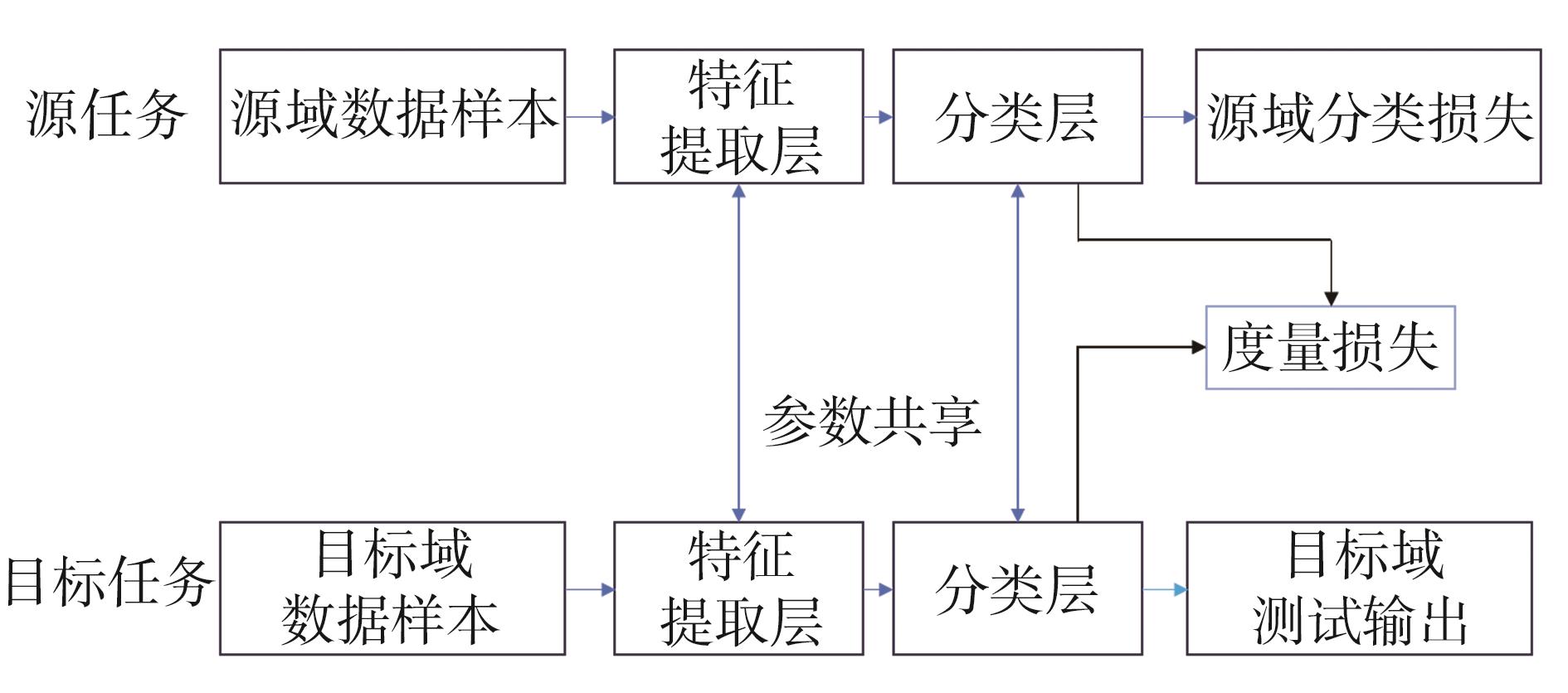
图6 特征迁移过程示意图
Fig. 6 Schematic diagram of the feature transfer process
领域自适应是特征迁移学习的主要方法之一,应用于源域数据和目标域数据的样本特征空间相同,但概率分布有差异的情形,其主要思路是将不同领域的数据特征映射到同一个特征空间,这样可利用其他领域数据来增强目标领域训练,域自适应示意图如
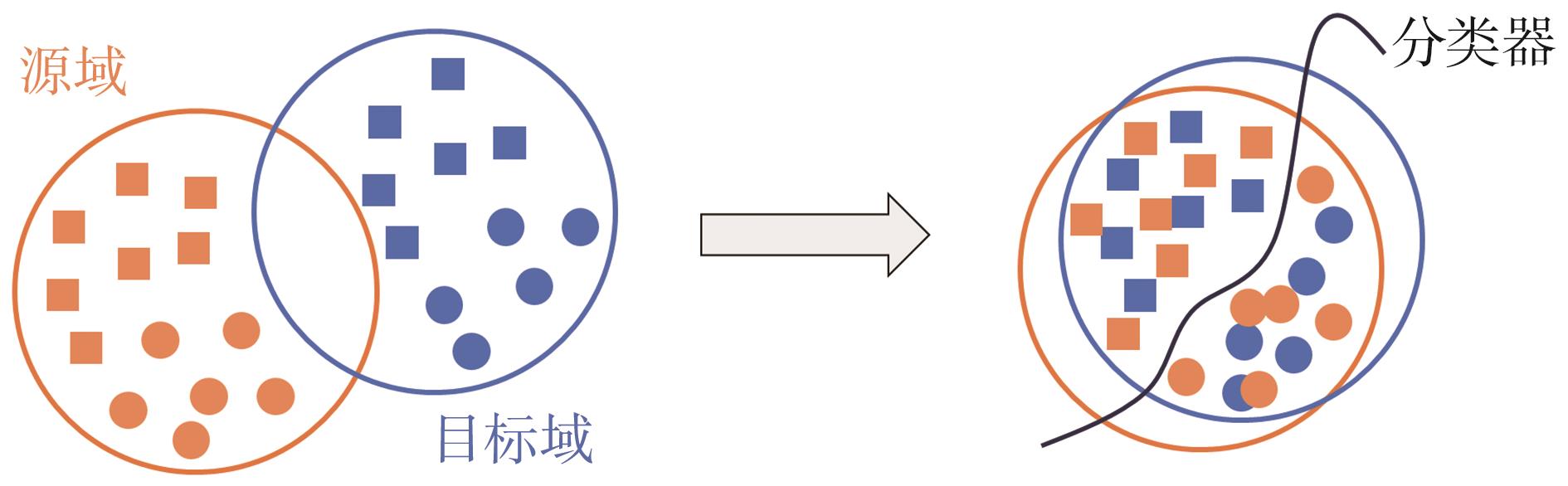
图7 域适应示意
Fig. 7 Schematic diagram of domain adaptatio
进行有效域自适应的前提条件是能准确度量源域和目标域之间的差异。深度学习方法中的自适应层可实现源域和目标域数据的自适应匹配,自适应过程使源域和目标域的数据分布更接近,从而提高网络的分类效果,而自适应方法的选取则决定了模型的泛化效果。KL散度(kullback-leibler divergence)、马氏距离、最大均值差异(MMD)、多核最大均值差异(multiple kernel maximum mean discrepancy,MK-MMD)等均可以充当距离函数度量。作为常用的度量方法,MMD将向量映射到再生希尔伯特空间中,计算2个概率分布P和Q在该空间中的分布距离,给定由P和Q采样生成的样本集X和Y,其MMD距离为X和Y在映射到再生希尔伯特空间H后的期望差异,MMD计算如
| (1) |
式中,表示样本集X中的第i个样本;表示样本集Y中的第j个样本;m和n分别表示样本集X和Y的样本个数;表示特征映射函数。
基于深度特征迁移理论,可通过引入不同的距离度量方法将不同工况的数据集映射到同一特征空间,使源域和目标域的数据在这个特征空间内达到相似的分布。其算法具体流程如
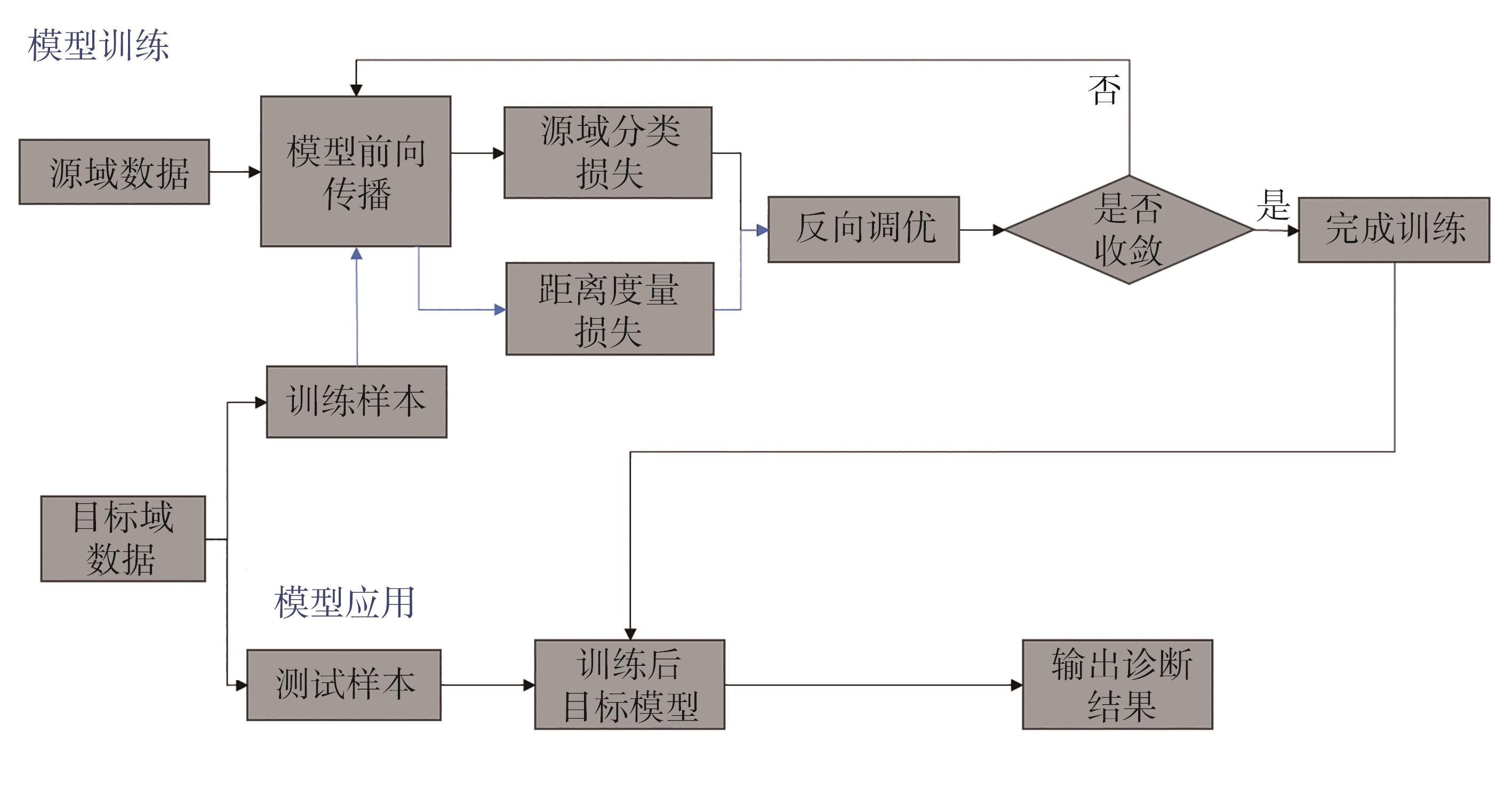
图8 特征迁移故障诊断流程图
Fig. 8 Flowchart of feature transfer fault diagnosis
在上文工况划分阶段,根据定量参数将生产运行数据分为多种不同工况,同时在不同工况的数据基础上分别进行建模,其中工况A的数据量最大,工况B的数据量次之,工况C的数据量最少。以数据量较大的工况数据为源域,以数据量较低的工况数据为目标域,实验跨工况的断纸故障诊断方案。本实验设置A→B,A→C及B→C 3种迁移学习任务,将其分别设为任务1、任务2及任务3,并分别基于参数迁移和特征迁移方法,验证所构建的迁移学习模型的可行性。
对于源域模型与目标域模型,沿用前期研
| 任务1(A→B) | 任务2(A→C) | 任务3(B→C) | |
|---|---|---|---|
| 准确率/% | 97.1 | 81.0 | 85.7 |
由
以任务1为例,将训练完成的工况A故障诊断模型的特征提取层参数权重迁移到工况B,并采用工况B下的微调样本数据更新分类层的权重。在完成训练后将微调后的模型用于工况B测试样本的状态识别并输出故障诊断准确率,其随迭代次数的变化过程如
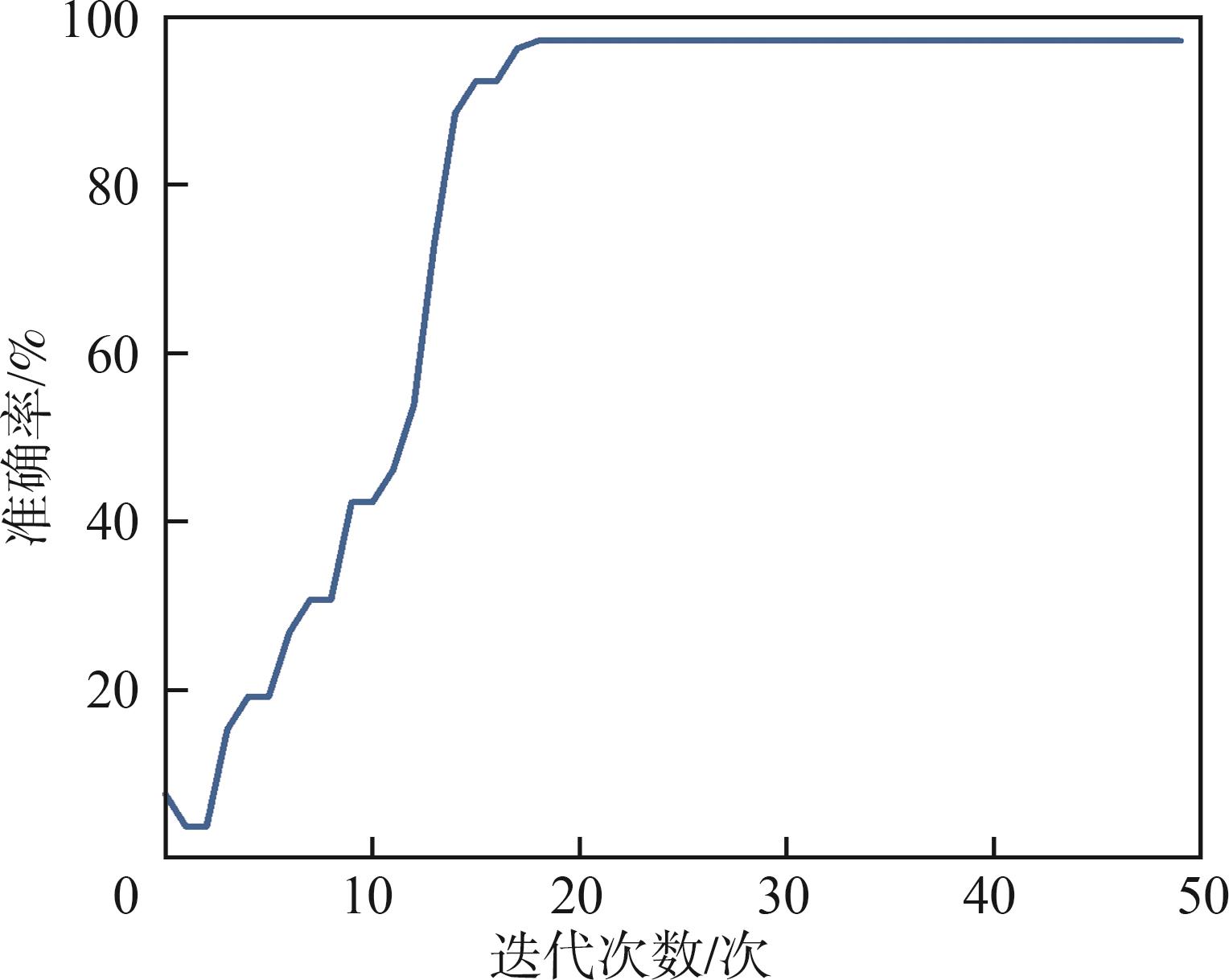
图9 参数迁移故障诊断模型训练过程
Fig. 9 Fault diagnosis model training based on parameter transfer model
由
在上述研究基础上,为探究微调样本个数对于诊断结果的影响,引入对比实验,分析在不同的微调样本个数下训练得到的目标模型效果。由于微调样本数目不同,模型所需的最大迭代次数存在差异。同时在训练过程中可能会出现过拟合现象,故在本实验中,在迭代过程中选择准确率的最大值,以此探索带标签样本数目对于模型诊断效果的影响。分别设置微调样本数为10、15、20、25个,研究在不同数量的带标签样本下,对模型进行微调的效果。微调样本参与训练过程,剩余样本用于测试模型的效果。
| 微调样本数/个 | 模型准确率/% | ||
|---|---|---|---|
| 任务1(A→B) | 任务2(A→C) | 任务3(B→C) | |
| 10 | 88.2 | 69.5 | 71.4 |
| 15 | 93.7 | 72.9 | 76.2 |
| 20 | 97.1 | 78.3 | 81.8 |
| 25 | 96.1 | 81.0 | 85.7 |
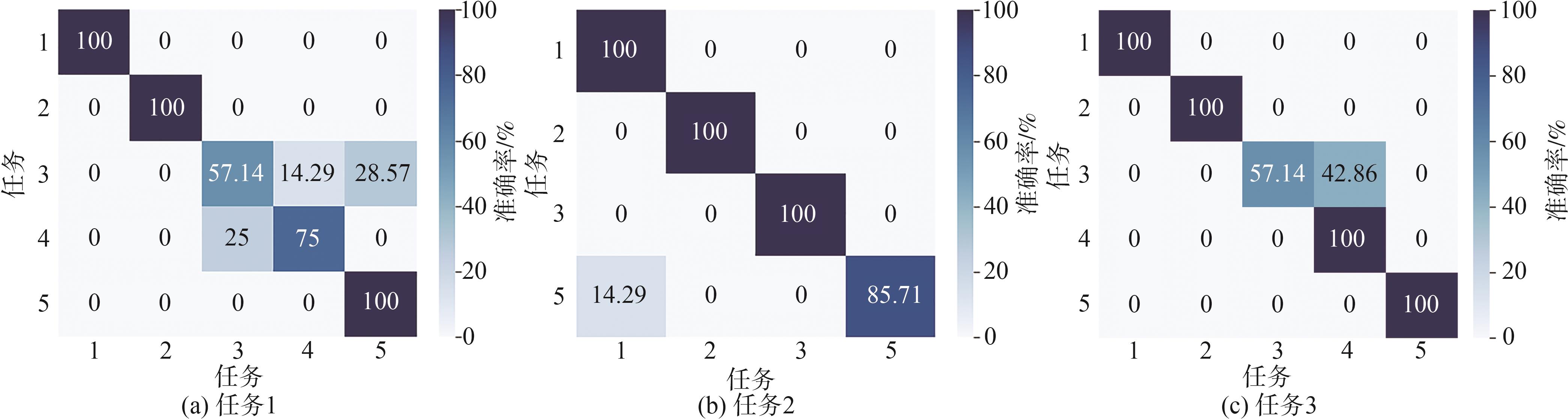
图10 不同迁移任务下的诊断结果
Fig. 10 Confusion matrix of diagnosis results under different transfer tasks
在进行迁移学习前,通过MMD公式对不同工况的距离进行度量,结果如
| 任务1(A→B) | 任务2(A→C) | 任务3(B→C) |
|---|---|---|
| 0.058 3 | 0.052 9 | 0.021 8 |
从
| 诊断类型 | 任务1(A→B) | 任务2(A→C) | 任务3(B→C) |
|---|---|---|---|
| 准确率 | 98.3 | 94.6 | 96.4 |
| 召回率 | 98.2 | 95.0 | 96.7 |
| 精确度 | 98.6 | 95.3 | 96.6 |
从
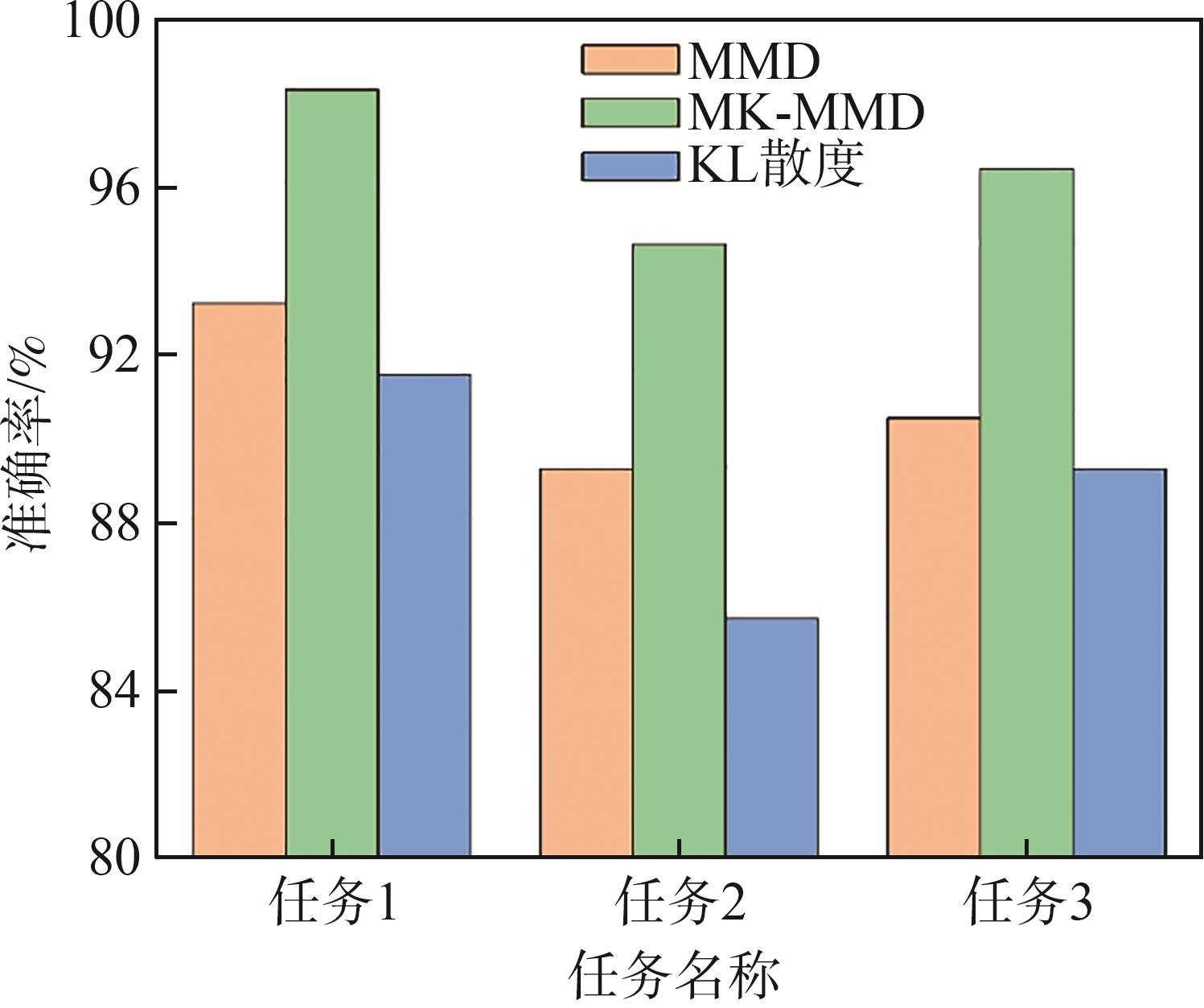
图11 在不同距离度量的故障诊断结果
Fig. 11 Fault diagnosis results under different distance metric methods
从
为实现跨工况故障诊断的需求,本课题分别基于参数迁移与特征迁移2种方法搭建了基于堆栈自编码器(SAE)和Softmax分类器故障诊断迁移模型。参数迁移模型主要通过特征提取层参数权重冻结以及分类层权重微调的方式,实现跨工况下的故障诊断;特征迁移模型主要通过空间距离度量方法适配特征空间的分布,以提升诊断模型在不同工况下的效果。
4.1 通过多个跨工况下详细的实验分析得知,相对于未进行迁移的模型,本课题所建立的2种深度迁移模型在故障诊断的诊断准确率均有所提升,这表明将深度迁移学习应用于跨工况故障诊断中有具有较好的效果。对比基于参数迁移模型和基于特征迁移模型,基于特征迁移的诊断模型诊断表现更优越,在不同的迁移任务下分别达到了98.3%、94.6%、96.4%,实现了大部分样本的准确分类。这可能是因为当源任务和目标任务存在一定差距时,由于特征迁移方法侧重于迁移学习源任务中提取的通用特征表示,而不是直接迁移模型参数,这使模型能够更好地泛化到目标任务上,相较于参数迁移效果更好。
4.2 在2种迁移方法下均可以观察到,相较于任务2的诊断结果,任务3的诊断结果更佳,而工况A和工况C之间的距离度量相较于工况B和工况C之间的距离度量更大,这说明迁移学习模型的表现会受到源域与目标域之间差异大小的影响,数据集本身也会对模型诊断效果有一定程度的影响。
从生产过程中进行现场标注的故障标签数据比基于数据分析获得的标签更可靠,且纸浆原料的相关数据中可能存在部分导致断纸故障的关键变量,未来研究应尝试将这些因素考虑在内。同时,后续研究工作可尝试将其推广至工业、文化等领域的其他纸种。
参考文献
中国造纸协会. 中国造纸工业 2022 年度报告[J]. 造纸信息, 2023(5):6-17. [百度学术]
China Paper Association. The Annual Report of China’s Papermaking Industry of 2022[J]. China Paper Newsletters, 2023(5):6-17. [百度学术]
HE Z L, QIAN J W,LI J G, et al. Data-driven soft sensors of papermaking process and its application to cleaner production with multi-objective optimization[J]. Journal of Cleaner Production, DOI: 10.1016/j.jclepro.2022.133803. [百度学术]
HE Z L, CHEN G J, HONG M N, et al. Process Monitoring and Fault Prediction of Papermaking by Learning from Imperfect Data [J]. IEEE Transaction of Automation Science and Engineering, DOI:10.1109/TASE.2023.3290552. [百度学术]
雷亚国,贾峰,孔德同,等.大数据下机械智能故障诊断的机遇与挑战[J].机械工程学报,2018,54(5):94-104. [百度学术]
LEI Y G, JIA F, KONG D T, et al. Opportunities and Challenges of Machinery Intelligent Fault Diagnosis in Big Data Era[J]. Journal of Mechanical Engineering, 2018, 54(5):94-104. [百度学术]
曲蕴慧, 汤伟, 成爽爽. 基于卷积神经网络及迁移学习的纸病分类方法研究[J]. 中国造纸, 2021, 40(10):63-70. [百度学术]
QU Y H, TANG W, CHENG S S. Paper Defects Classification Based on Deep Convolution Neural Network[J]. China Pulp & Paper, 2021,40(10):63-70. [百度学术]
XIAO Y, ZHOU X, ZHOUO H, et al. Multi-label deep transfer learning method for coupling fault diagnosis[J]. Mechanical Systems and Signal Processing, DOI:10.1016/j.ymssp.2024.111327. [百度学术]
LI Y, SONG Y, JIA L, et al. Intelligent Fault Diagnosis by Fusing Domain Adversarial Training and Maximum Mean Discrepancy via Ensemble Learning[J]. IEEE Transactions on Industrial Informatics, 2021, 17(4): 2833-2841. [百度学术]
WANG Z. A deep transfer learning method for system-level fault diagnosis of nuclear power plants under different power levels[J]. Annals of Nuclear Energy , DOI:10.1016/j.anucene.2021.108771. [百度学术]
LI J, LIN M, LI Y, et al. Transfer learning network for nuclear power plant fault diagnosis with unlabeled data under varying operating conditions[J]. Energy, DOI: 10.1016/j.energy.2022. 124358. [百度学术]
杜建,张磊,李继庚,等.基于GMM-MD组合算法的过程工业故障预测模型[J].中国造纸学报,2022,37(2):81-86. [百度学术]
DU J, ZHANG L, LI J G, et al. Fault Prediction Model for Process Industry Based on GMM-MD Combinational Algorithm[J]. Transaction of China Pulp and Paper, 2022,37(2):81-86. [百度学术]
陈国健,李继庚,陈波,等.基于自编码的长流程造纸过程断纸故障识别[J].中国造纸,2024,43(3):113-120. [百度学术]
CHEN G J, LI J G, CHEN B, et al. Paper Break Fault Recognition in Long Process Papermaking Process Based on Autoencoder[J]. China Pulp & Paper,2024,43(3):113-120. [百度学术]
徐玲玲, 迟冬祥. 面向不平衡数据集的机器学习分类策略[J]. 计算机工程与应用, 2020,56(24): 12-27. [百度学术]
XU L L, CHI D X. Machine Learning Classification Strategy for Lmbalanced Data Sets[J]. Computer Engineering and Application, 2020,56(24): 12-27. [百度学术]
RAZA A, TRAN K, KOEHL L, et al. Knowledge-based Systems Designing ECG Monitoring Healthcare System with Federated Transfer Learning and Explainable AI[J]. Knowledge-based System, DOI: 10.1016/j.knosys.2021.107763. [百度学术]
JIANG F, LIN W, WU Z, et al. Fault diagnosis of gearbox driven by vibration response mechanism and enhanced unsupervised domain adaptation[J]. Advanced Engineering Informatics, DOI: 10.1016/j.aei.2024.102460. [百度学术]
XU S, YAO Y, YONG N, et al. Intelligent multi-severity nuclear accident identification under transferable operation conditions[J]. Annals of Nuclear Energy, DOI:10.1016/j.anucene.2024. 110416. [百度学术]