摘要
本课题提出了一种基于多智能体深度强化学习的动态优化方法,以期实现造纸废水处理过程的运行成本和能耗的协同优化。实验采用了基准仿真1号模型(BSM1)模拟造纸废水处理过程的生化反应和沉淀过程,并利用模型数据对强化学习智能体进行训练,最后用实际的造纸废水数据对搭建的模型系统进行验证。结果表明,基于多智能体深度强化学习的废水处理系统能够保障排水质量,实现成本与能耗的多目标优化控制,其性能表现优于传统方法。
中国的造纸工业发展迅速,近5年内,纸和纸板的产量以高于3.9%的年均速度持续增长,预计在未来较长时间内,中国造纸行业仍将随着中国经济的稳定增长而不断发
我国森林资源匮乏,利用废纸造纸是我国造纸工业的主要生产途径。2020年底,为深入推进节约用水工作,水利部联合工信部印发了《工业用水定额:造纸》的通知,要求脱墨废纸浆用水定额20~25
在此背景下,如何管理造纸废水处理过程,对造纸废水的排放质量与处理产生的成本和能耗进行协调,形成了一个带约束的多目标优化问题。相关研究中,对废水处理过程形成的复杂系统问题多通过模型模拟的方式进行处理和解
针对相关的优化问题研究,学者们提出了一系列的数学规划模型。Zhang等
多智能体系统具有平行计算和经验分享等优势,考虑到多智能体强化学习(MARL)在处理多目标优化问题上所具备的以上优异性能,本课题拟应用多智能体深度强化学习,在BSM1模拟活性污泥法的造纸废水处理过程的基础上,建立以出水水质为依据,实现废水处理过程的运行成本与能耗优化为目标的造纸废水多目标优化模型,为造纸行业提质增效提供一定的参考。
活性污泥法的造纸废水处理过程主要包括生化反应池和二沉池。为了客观评价废水处理过程的控制策略,本课题选择BSM1作为废水生化过程模型,其具体布局如
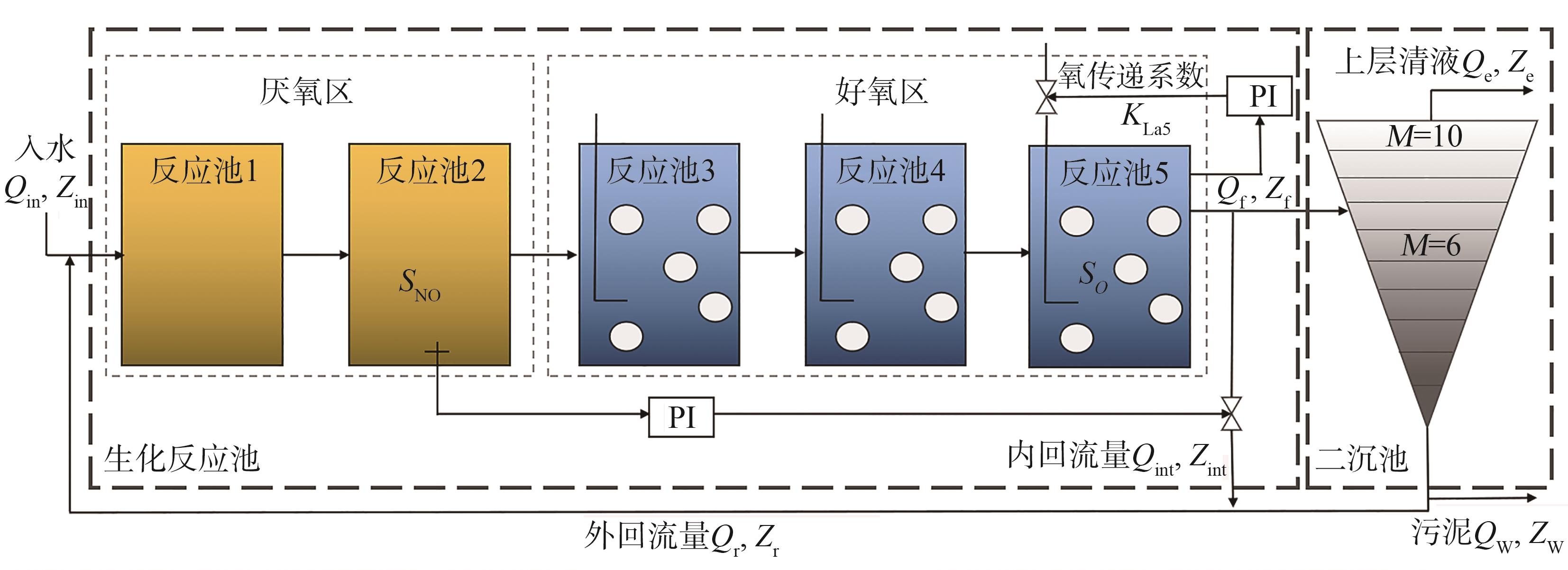
图1 BSM1的系统结构图
Fig. 1 System structure diagram of BSM1
为了评估废水处理过程的控制策略,本课题在BSM1模型的基础上,主要考虑了污泥排放量(Sludge Production,SP)所产生的运行成本Cost。其运行成本具体评价标准如式(1)~
| Cost = SP | (1) |
| SP = | (2) |
式中,TSS为固体悬浮物浓度;XS,w、XI,w、XB,H,w、XB,A,W分别为废淤泥中易降解颗粒组分、难降解颗粒组分、异养菌浓度和自养菌浓度;为废淤泥流量。
与运行成本相类似,根据BSM1模型的评价标准,对废水处理过程的能耗求解可以考虑曝气能耗(Aeration Energy,AE)、泵送能耗(Pumping Energy,PE)和混合能耗(Mixing Energy,ME)3个方面,如式(3)~
| 总能耗 = AE + PE + ME | (3) |
| AE = | (4) |
| (5) |
| ME = | (6) |
式中,为溶解氧的饱和浓度;为第k个反应池的容积,为第k个反应池的氧传递系数;和分别为内循环流量和回流污泥循环流量。
出水水质是否达标是评价废水处理过程好坏的关键,本课题采用了多个水质参数的限制范围。参考BSM1模型中具备的动态过程参数,除外,其出水水质具体计算过程可归纳为式(7)~
| (7) |
| (8) |
| (9) |
| (10) |
式中,和为化学计量参数,分别表示微生物细胞中氮含量比例、微生物产物中氮含量比例、微生物中惰性颗粒比例,其值分别为0.08 gN/gCOD、0.06 gN/gCOD和0.08。
在所搭建的造纸废水处理模型的基础上,本课题主要对 2个关键控制参数进行了调控。由于不同的控制策略对造纸废水处理过程的运行成本、能耗以及出水水质等均有较大的影响,对这些关键控制变量进行实时优化将显著降低生产成本和能源消耗。根据上述内容,本课题将这一优化问题归纳出以下目标函数,如式(11)~
| (11) |
| (12) |
| (13) |
式中,、分别为造纸废水处理过程运行成本、能耗的总和函数,、分别为受控制参数影响的相关因子集。
当的定义域为和(的范围为0~100000
| (14) |
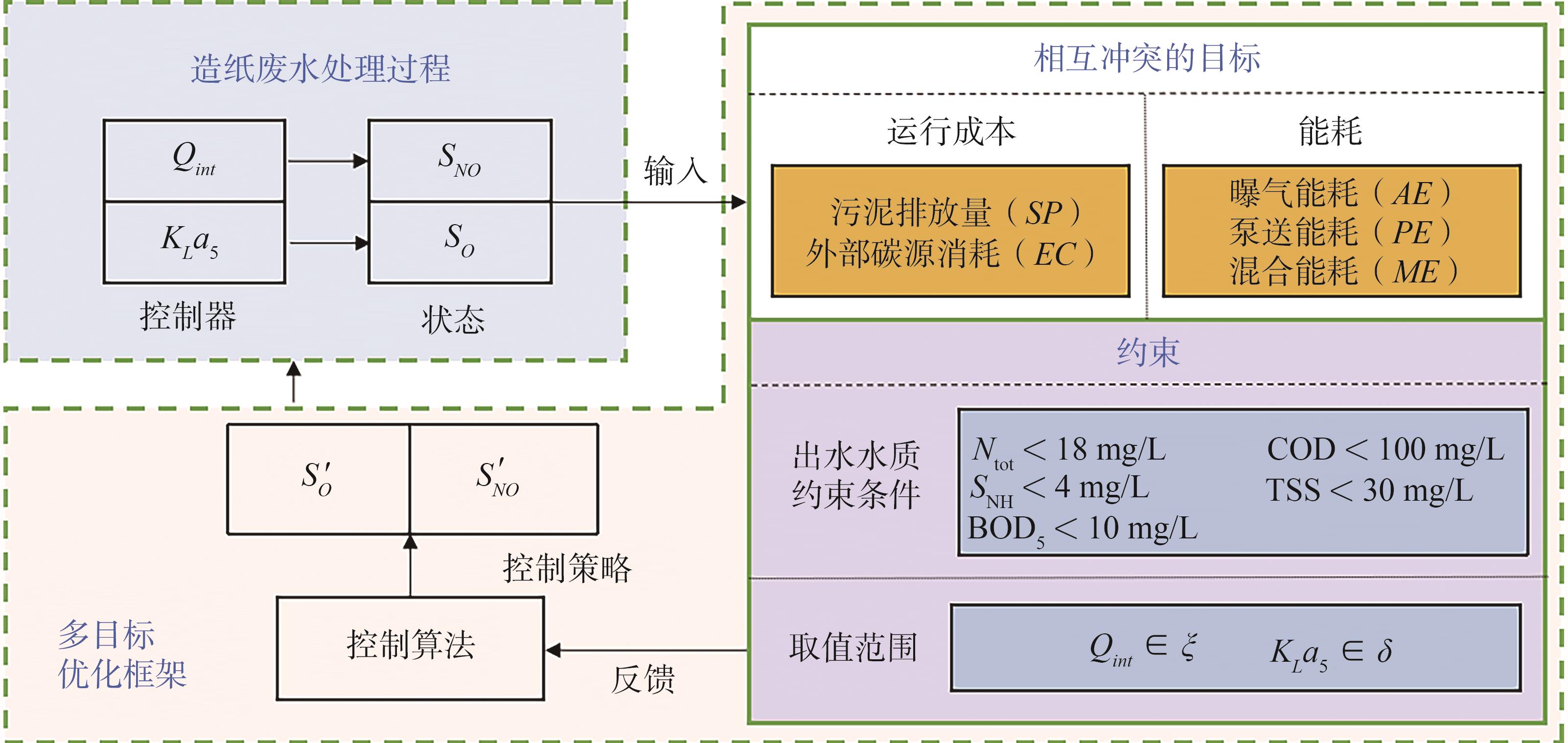
图2 造纸废水处理过程多目标优化流程图
Fig. 2 Flowchart of multi-objective optimization for papermaking wastewater treatment process
上述造纸废水处理过程的多目标优化问题可以看作是双智能体的非零和随机博弈。其中,2个智能体通过分别选择做出动作,从环境(造纸废水处理过程)中依据
MARL系统考虑目标的最优管理和废水处理过程的优化问题,形成一个造纸废水处理过程优化问题的马尔可夫博弈框架(见
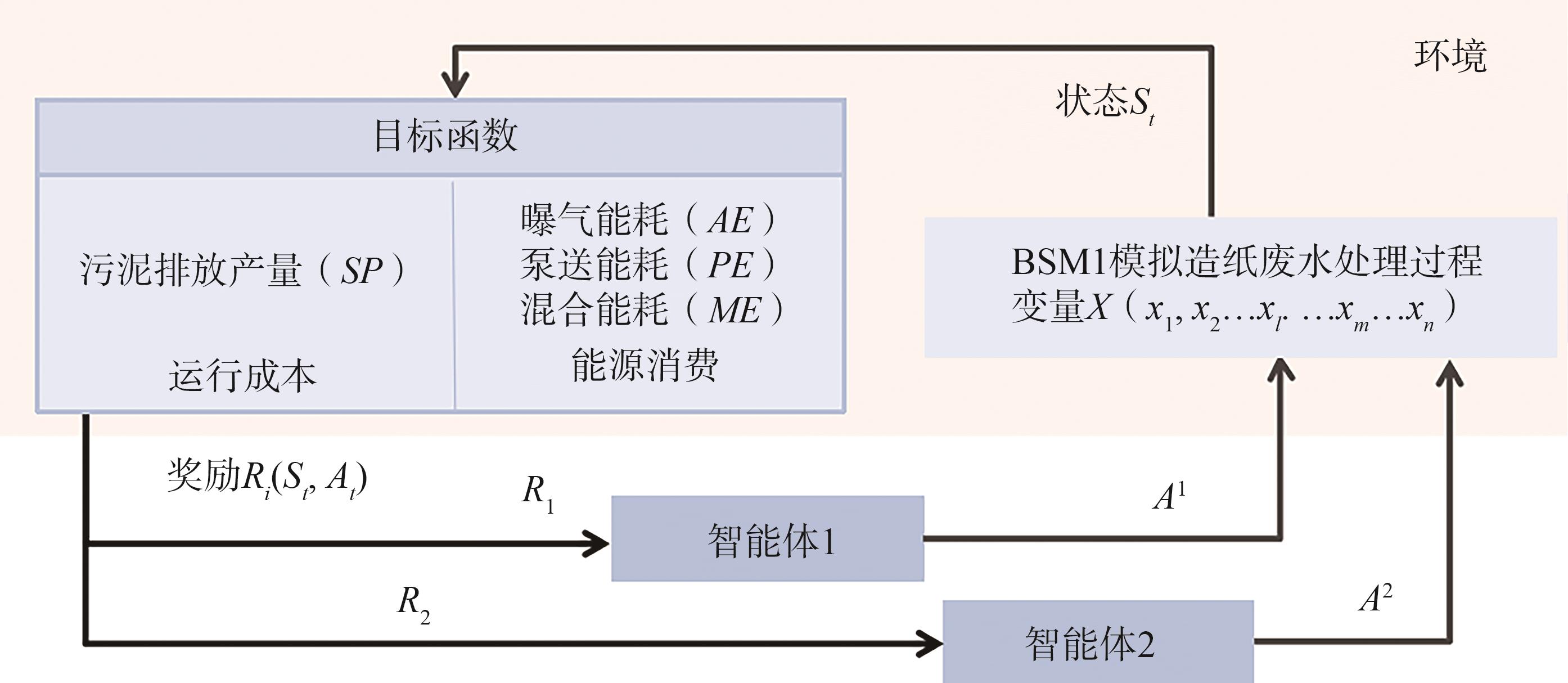
图3 造纸废水处理过程优化问题的马尔可夫博弈框架
Fig. 3 Markov Game framework of paper wastewater treatment process optimization problem
强化学习智能体通过对状态的观察,训练得出在当前环境中的最优选择,并从独立积累的奖励中优化策略。在废水处理过程中智能体通过控制和来调节反应池2的NO浓度SNO和反应池5的溶解氧浓度SO,故可将智能体的动作定义为
| (16) |
状态转移概率是智能体在t时刻选择动作A,从转移到下一个状态的概率。通过状态转移评估智能体的表现,可以帮助智能体更快地收敛到最优控制策略。对于所有满足上述优化问题中约束的动作和状态,如
| > 0和 | (17) |
实际工业过程一般可被看作是随时间连续分布的规模较大的动作-状态空间系统,应用强化学习算法时,传统Q-learning容易面临维度灾难,无法求解。因此,有学
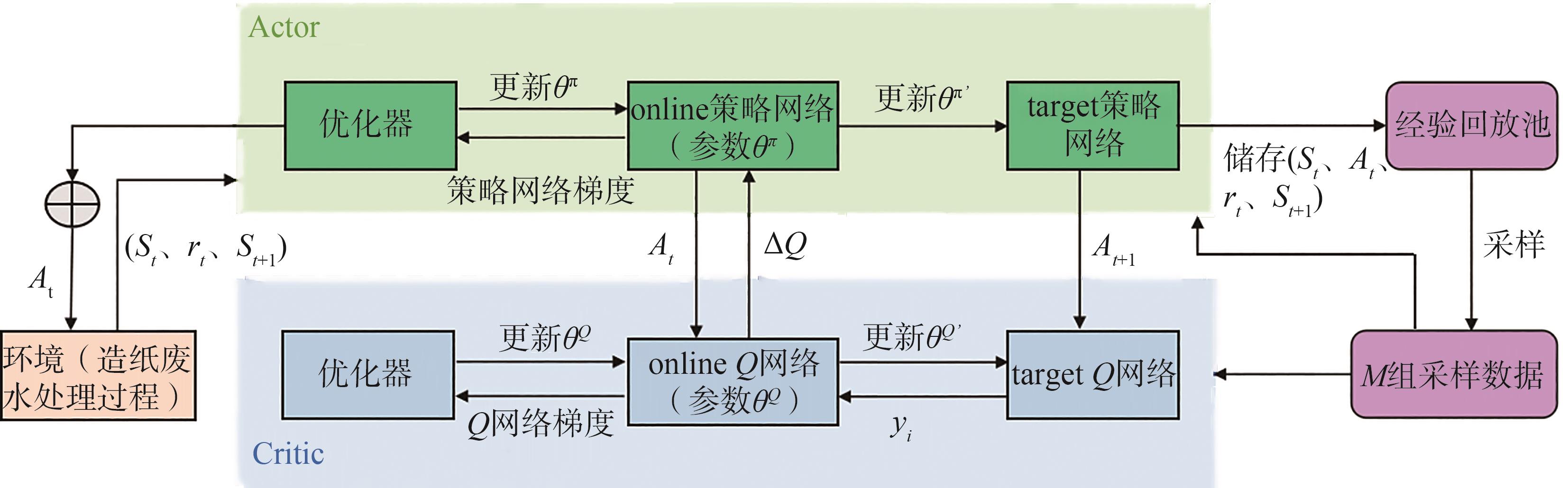
图4 MARL系统中运行DDPG算法的流程图
Fig. 4 Flow chart of running DDPG algorithm in MARL system
当前研究随机选取了BSM1模型中不同天气情况下的入水数据组合,对智能体进行了训练,使其在应用环境中针对目标的控制策略进行收敛。收敛后,利用从广东省某造纸厂入水现场监测系统所采集的140 h废水入水数据(如

图5 造纸废水处理过程入水数据
Fig. 5 Inflow data of papermaking wastewater treatment process
| 检测项目 | COD | TSS | TN | SNH | SO | 流量 |
|---|---|---|---|---|---|---|
| 检测方法 | 重铬酸钾法 | 质量量法 | 碱性过硫酸钾消解紫外分光光度法 | 纳式试剂分光光度法 | 荧光法 | |
| 检测标准或仪器 | GB 11914—89 | GB 11901—1989 | HJ 636—2012 | HJ 535—2009 |
JY-DY2900 溶解氧仪 | 电磁流量计 |
| (19) |
| (20) |
| (21) |
| (22) |
| (23) |
| (24) |
| (25) |
本研究利用BSM1模型的入水数据训练智能体,训练过程中系统参数的设置如
| 抽取样本M | 经验池D | Actor学习率A | Critic学习率c | 折扣因子 | 步长数N | 内部循环流量 | 氧传递系数 |
|---|---|---|---|---|---|---|---|
| 128 |
1 | 0.0001 | 0.001 | 0.99 | 6720 |
[0,1 | [0,242] |
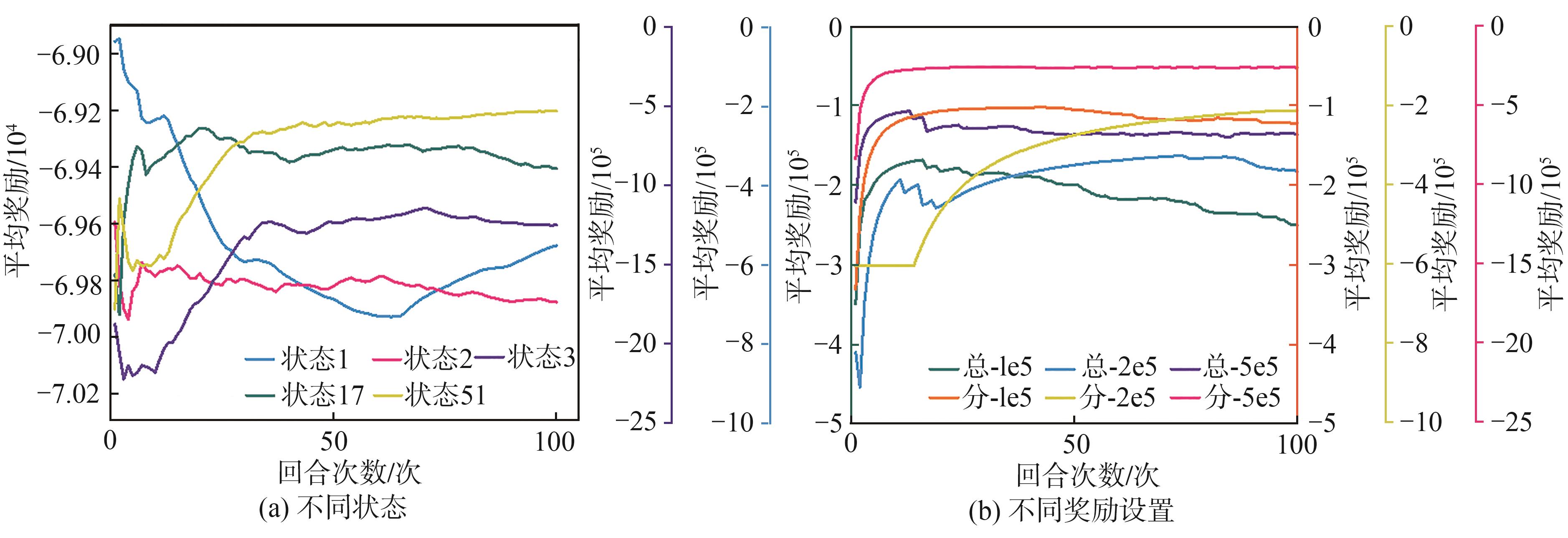
图6 智能体在不同状态和不同奖励设置下的平均奖励训练追踪图
Fig. 6 Average reward training tracking graph of the agent in different states and different reward Settings
从
在
以上述最终获得的智能体(51维状态、奖励-5e5平均分配)为例,
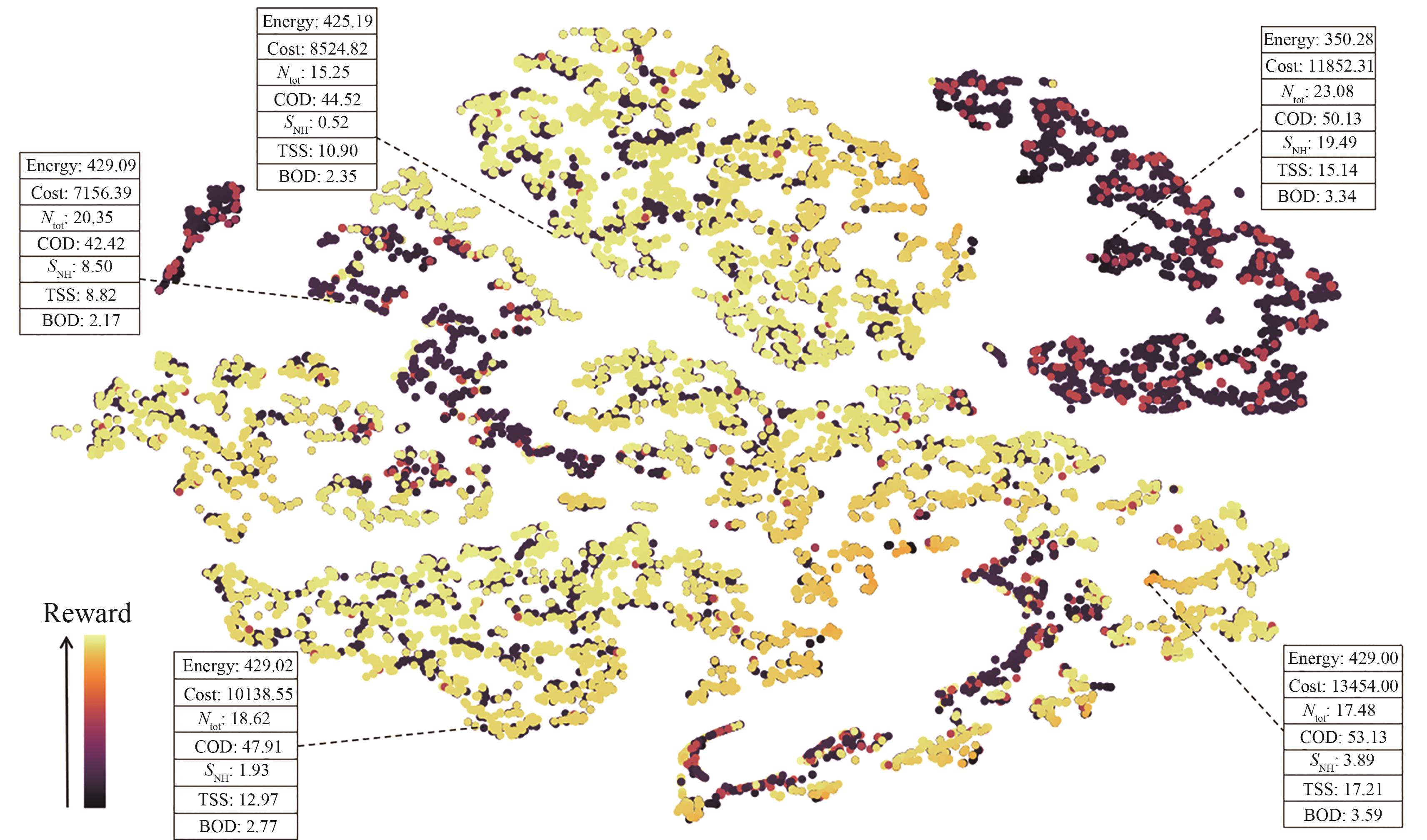
图7 经验状态的二维t-SNE图
Fig. 7 Two-dimensional t-SNE diagram of the experienced state
根据前文所述出水水质标准和式(7)~
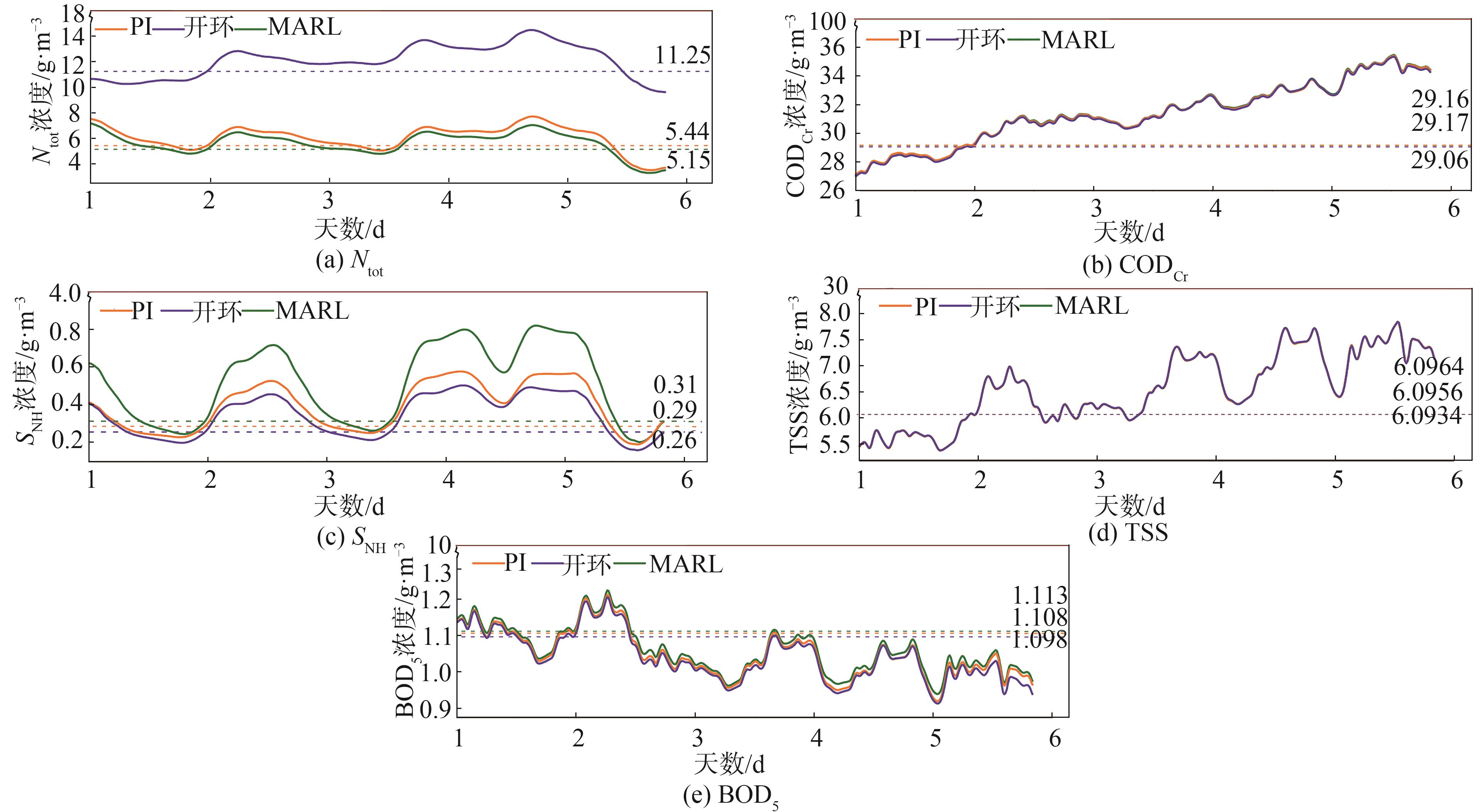
图8 MARL、开环和PI控制器的出水水质比较
Fig. 8 Comparison of effluent quality among the proposed model, open-loop, and PI-controller
运行成本主要考虑了污泥排放量SP。以PI控制器为基准,
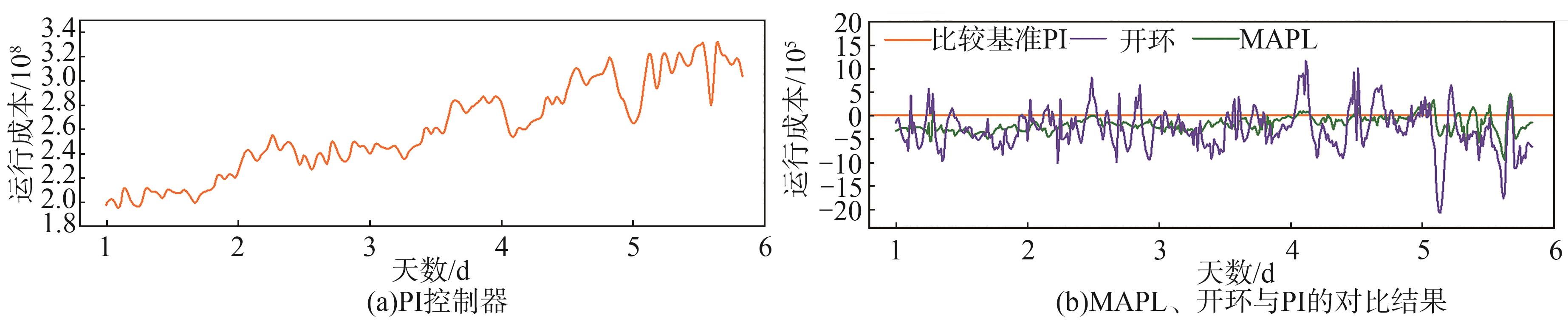
图9 MARL、开环和PI控制器的运行成本比较
Fig. 9 Comparison of operational cost among the proposed model, open-loop, an PI-controller
能耗是造纸废水处理过程中最受关注的问题之一。

图10 MARL、开环和PI控制器的曝气能耗比较
Fig. 10 Comparison of aeration energy among the proposed model, open-loop, and PI-controller

图11 MARL、开环和PI控制器的混合能耗比较
Fig. 11 Comparison of mixing energy among the proposed model, open-loop, and PI-controller
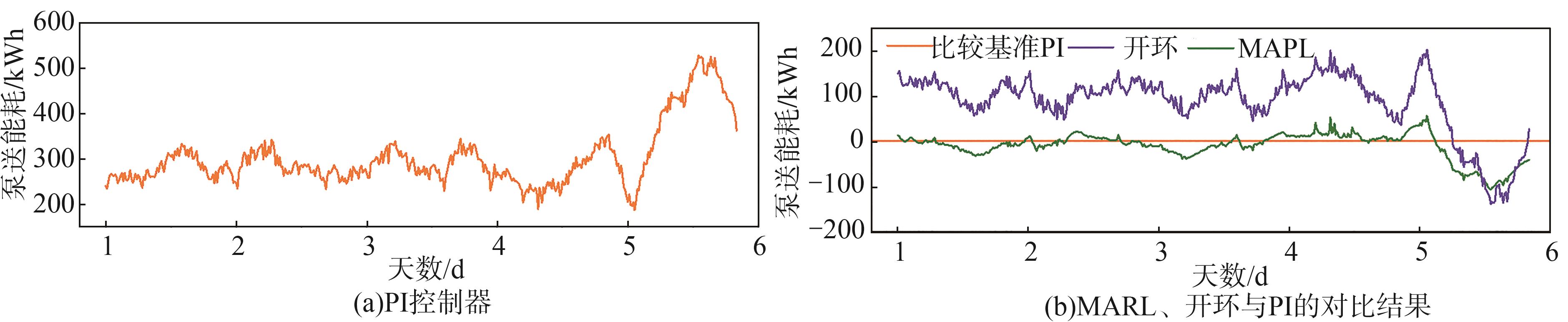
图12 MARL、开环和PI控制器的泵送能耗比较
Fig. 12 Comparison of pumping energy among the proposed model, open-loop, and PI-controller
本课题基于多智能体系统和深度强化学习,提出了一种基于多智能体强化学习(MARL)的方法,将当前的造纸废水多目标优化问题构建为马尔可夫博弈过程,并利用深度强化学习深度Q网络(DQN)算法协同求解最优控制策略,从而达到优化造纸废水处理过程的目的,使其更经济、更节能、更环保。具体操作如下:以造纸废水处理厂采集的实际数据为基础,利用基准仿真1号模型(BSM1)对所搭建的MARL多目标优化模型进行了模拟验证,并将验证效果与开环、PI控制器进行了比较,探讨了采用MARL的方法实现废水处理过程的多目标优化的潜力。
3.1 以PI控制器的结果为基准,MARL系统的运行成本整体上比PI控制器低,至少节省平均3.5×1
3.2 以PI控制器为基准,比较了MARL系统与开环、PI控制器的应用效果。实验结果表明,开环、PI控制器和MARL系统3种不同场景下的平均能耗分别为3969、3578和3561 kWh,其中MARL系统比PI控制器平均节能17 kWh,表明了所建立的MARL系统对造纸废水处理过程能耗优化的有效性。
本课题研究仍存在一些不足,后期将针对这些方面的不足进行更为深入的研究。
(1)前期的部分工作验证了针对造纸废水处理过程对BSM1进行修正的重要性。但本课题在BSM1仿真模型搭建过程中,仅侧重于建立新型控制方法,在模型训练和验证过程中对部分实验条件进行了简化或理想化的处理,未能充分反映造纸废水的特性,这一点需要在未来工作中加强重视和深入探究。
(2)优化所提出的MARL系统,需对模型的奖励函数结构、状态设置及智能体参数进行更广泛的实验讨论。
(3)在运行成本和能耗之外,需同时考虑环境因素,尝试求解最优控制策略。
(4)需考虑更多控制器的应用场景,使提出的多智能体深度强化学习系统更贴近工业生产实际。
参 考 文 献
Man Y, Li J, Hong M, et al. Energy transition for the low-carbon pulp and paper industry in China[J]. Renewable & Sustainable Energy Reviews, DOI: 10.1016/j.rser.2020.109998. [百度学术]
中国造纸工业可持续发展白皮书[J]. 造纸信息, 2019(3):10-19. [百度学术]
White Paper on Sustainable Development of China’s Paper Industry [J]. China Paper Newsletters, 2019(3):10-19. [百度学术]
水利部、工业和信息化部发布造纸等七项工业用水定额[J]. 造纸信息, 2021(1):15. [百度学术]
Ministry of Water Resources and Ministry of Industry and Information Technology Issued Seven Industrial Water Quotas for Papermaking [J]. China Paper Newsletters, 2021(1):15. [百度学术]
张珈铭, 周晨旭, 熊建华, 等. 废纸回用废水中胶黏物去除技术研究进展[J]. 中国造纸, 2022, 41(6):103-112. [百度学术]
ZHANG J M, ZHOU C X, XIONG J H, et al. Study on Removal of Stickies in Waste Paper Recycling Wastewater[J].China Pulp & Paper,2022,41(6):103-112. [百度学术]
Shen W, Chen X, Corriou J P. Application of model predictive control to the BSM1 benchmark of wastewater treatment process[J]. Computers & Chemical Engineering, 2008,32(12):2849-2856. [百度学术]
徐峻, 李军, 陈克复. 制浆造纸行业水污染全过程控制技术理论与实践[J]. 中国造纸, 2020,39(4):69-73. [百度学术]
XU J, LI J, CHEN K F. Whole-process Control of Water Pollution in Theory and Practice for Pulp and Paper Industry[J].China Pulp & Paper,2020,39(4):69-73. [百度学术]
Wang Z, Man Y, Hu Y, et al. A deep learning based dynamic COD prediction model for urban sewage[J]. Environmental Science Water Research & Technology, 2019,5(12):221-228. [百度学术]
Man Y, Shen W, Chen X, et al. Dissolved oxygen control strategies for the industrial sequencing batch reactor of the wastewater treatment process in the papermaking industry[J]. Environmental Science Water Research & Technology, 2018,4(5):654-662. [百度学术]
王爱其, 陈科. 自适应粒子群算法在污水处理过程智能控制优化中的应用仿真研究[J].中国造纸, 2021, 40(8): 70-74. [百度学术]
WANG A Q, CHEN K. Application Simulation Research of Adaptive Particle Swarm Optimization in Intelligent Control Optimization of Wastewater Treatment Process[J]. China Pulp & Paper,2021, 40(8):70-74. [百度学术]
Flores-Alsina X, Rodríguez-Roda I, Sin G, et al. Multi-criteria evaluation of wastewater treatment plant control strategies under uncertainty[J]. Water Research, 2008,42(17):4485-4497. [百度学术]
Flores-Alsina X, Corominas L, Snip L, et al. Including greenhouse gas emissions during benchmarking of wastewater treatment plant control strategies[J]. Water Research, 2011,45(16):4700-4710. [百度学术]
Zhang Y, Hong M, Li J, et al. Energy system optimization model for tissue papermaking process[J]. Computers & Chemical Engineering, DOI: 10.1016/j.compchemeng.2020.107220. [百度学术]
Bozkurt H, Quaglia A, Gernaey K V, et al. A mathematical programming framework for early stage design of wastewater treatment plants[J]. Environmental Modelling & Software, 2015,64:164-176. [百度学术]
Wang K, Wang P, Nguyen H. A data-driven optimization model for coagulant dosage decision in industrial wastewater treatment[J]. Computers & Chemical Engineering, DOI:10.1016/j.compchemeng.2021.107383. [百度学术]
Janga Reddy M, Nagesh Kumar D. Evolutionary algorithms, swarm intelligence methods, and their applications in water resources engineering: A state-of-the-art review[J]. H2Open Journal, 2020,3(1):135-188. [百度学术]
Nayak M, Dhanarajan G, Dineshkumar R, et al. Artificial intelligence driven process optimization for cleaner production of biomass with co-valorization of wastewater and flue gas in an algal biorefinery[J]. Journal of Cleaner Production, 2018,201:1092-1100. [百度学术]
Man Y, Hu Y, Ren J. Forecasting COD load in municipal sewage based on ARMA and VAR algorithms[J]. Resources, Conservation and Recycling, 2019,144:56-64. [百度学术]
Dai M, Yang F, Zhang Z, et al. Energetic, economic and environmental (3E) multi-objective optimization of the back-end separation of ethylene plant based on adaptive surrogate model[J]. Journal of Cleaner Production, DOI:10.1016/j.jclepro.2021.127426. [百度学术]
Hanafi S, Todosijević R. Mathematical Programming Based Heuristics for the 0-1 MIP: A Survey[J]. Journal of Heuristics, 2017,23(4):165-206. [百度学术]
张爱娟, 胡慕伊, 黄亚南, 等. 基于专家前馈-模糊PID反馈的溶解氧浓度控制方案研究[J]. 中国造纸学报, 2016,31(2):43-48. [百度学术]
ZHANG A J, HU M Y, HUANG Y N, et al. Dissolved Oxygen Concentration Control System Based on Expert feedforward and Fuzzy PID Feed-back Control[J]. Transactions of China Pulp and Paper, 2016,31(2):43-48. [百度学术]
Wang Y, Liu H, Zheng W, et al. Multi-objective Workflow Scheduling with Deep-Q-Network-based Multi-agent Reinforcement Learning[J]. IEEE Access, 2019,7:39974-39982. [百度学术]
Mannion P, Devlin S, Duggan J, et al. Reward shaping for knowledge-based multi-objective multi-agent reinforcement learning[J]. Knowledge Engineering Review, DOI: 10.1017/S0269888918000292. [百度学术]
He Z, Qian J, Man Y, et al. Data-driven soft sensors of papermaking process and its application to cleaner production with multi-objective optimization [J]. Journal of Cleaner Production, DOI:10.1016/j.jclepro.2022.133803. [百度学术]
Hernández-del-Olmo F, Gaudioso E, Dormido R, et al. Tackling the start-up of a reinforcement learning agent for the control of wastewater treatment plants[J]. Knowledge-based Systems, 2018,144:9-15. [百度学术]
He Z, Tran K P, Thomassey S, et al. Multi-objective optimization of the textile manufacturing process using deep-Q-network based multi-agent reinforcement learning[J]. Journal of Manufacturing Systems, 2022,62:939-949. [百度学术]
Petsagkourakis P, Sandoval I O, Bradford E, et al. Reinforcement learning for batch bioprocess optimization[J]. Computers & Chemical Engineering, DOI: 10.1016/B978-0-12-818634-3.50154-5. [百度学术]
Li Weiye, Li Bin, He Songping, et al. A novel milling parameter optimization method based on improved deep reinforcement learning considering machining cost[J]. Journal of Manufacturing Processes, 2022, 84: 1362-1375. [百度学术]
Han Xiaoyun, Mu Chaoxu, Yan Jun, et al. An autonomous control technology based on deep reinforcement learning for optimal active power dispatch[J].International Journal of Electrical Power and Energy Systems, DOI: 10.1016/j.ijepes.2022.108686. [百度学术]
He Z, Tran K, Thomassey S, et al. A deep reinforcement learning based multi-criteria decision support system for optimizing textile chemical process[J]. Computers in Industry, DOI: 10.48550/arXiv.2012.14794. [百度学术]
Mnih V, Kavukcuoglu K, Silver D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015,518(7540):529-533. [百度学术]
Lillicrap T P, Hunt J J, Pritzel A, et al. Continuous control with deep reinforcement learning[J]. Computer Ence, DOI: 10.1016/S1098-3015(10)67722-4. [百度学术]
Man Y, Shen W, Chen X, et al. Modeling and simulation of the industrial sequencing batch reactor wastewater treatment process for Cleaner Production in pulp and paper mills[J]. Journal of Cleaner Production, 2017,167:643-652. [百度学术]
黄菲妮. 造纸污水生化处理过程温室气体减排的溶解氧优化控制[D]. 广州:华南理工大学, 2020. [百度学术]
HUANG F N. Optimized Dissolved Oxygen Control for Greenhouse Gas Reduction in Wastewater Treatment Process of Paper Mill [D]. Guangzhou:South China University of Technology, 2020. [百度学术]
Marchesini E, Corsi D, Farinelli A. Benchmarking Safe Deep Reinforcement Learning in Aquatic Navigation[J]. Machine Learning, DOI: 10.48550/arXiv.2112.10593. [百度学术]
Van der Maaten L J P, Hinton G E. Visualizing High-dimensional Data Using t-SNE[J]. Journal of Machine Learning Research, 2008,9(11):2579-2605. [百度学术]
Chen K, Wang H, Valverde-Pérez B, et al. Optimal control towards sustainable wastewater treatment plants based on multi-agent reinforcement learning[J]. Chemosphere, DOI:10.1016/j.chemosphere.2021.130498. [百度学术]