
摘要
出水化学需氧量(COD)与出水固形物含量(SS)是评价造纸废水处理工艺好坏的重要指标。为了更好地对其进行预测,提出了一种基于随机森林(RF)模型的方法,并以R语言为工具进行回归预测。对比偏最小二乘(PLS)模型、支持向量回归(SVR)模型、人工神经网络(ANN)模型等常规预测模型,发现RF模型具有预测精度高,结果误差小,泛化能力好,调整参数少等优点。在对出水COD进行预测时,RF模型的相关系数r为0.7954,相比于PLS、SVR、ANN分别提高了8.88%、10.73%、14.68%。在对出水SS进行预测时,RF模型的相关系数r为0.8551,相比于PLS、SVR、ANN分别提高了15.43%、24.25%、30.79%。
在造纸废水处理工艺中,往往需要根据出水指标来及时调整工艺条件,达到对污水的安全排放。然而考虑到造纸废水处理过程中大多包含具有时变性与复杂性的化学过程,传统化学成分检测仪表存在价格高昂、维护成本高以及检测不灵敏等缺点。近年来,基于数据驱动的软测量建模方法可通过建立输入与输出数据的关系来完成易测变量对难测变量的预
常见的软测量建模方法有人工神经网络(Artificial Neural Networks, ANN)、支持向量回归(Support Vector Regression, SVR)、偏最小二乘法(Partial Least Squares, PLS
随机森林(Random Forest,RF)模型是由Leo Breiman与Adele Cutler在2001年提出的一种统计学习模
RF模型由K棵决策树
组成,其中
是一个随机变量序列。当模型用于分类时,RF模型中的决策树使用分类树(一般使用C4.5),最终通过少数服从多数的原则决定分类结果,当模型用于回归预测时,决策树使用回归树(一般用CART),最终将所有决策树输出值的平均值作为预测结
(1)Bagging思
在原始训练集中,利用Bootstrap抽样方法有放回地抽取若干个大小相同的数据集样本。原始训练集中每个样本未被抽到的概率为(1–1/N)
(2)随机特征思
为保证RF模型的随机性最大化,每棵树在节点分裂的过程中,都会从所有特征中选出最优特征作为参考指标。对于RF模型而言,如果选择过少的特征,则会导致模型的精度降低。如果选择的特征过多,则会弱化模型在分裂节点处的随机
(1)在原始训练集S中,通过Bootstrap重抽样的方法取出n个数据集样本,然后将每个数据集样本分为抽中样本即袋内数据(in-bag)和未被抽中样本即袋外数据(out-of-bag)。
(2)从样本的所有属性中随机抽取m个属性,根据Gini指标进行节点分裂,用袋内数据训练构建CART树。在构建的过程中不进行修剪,使得每一棵CART树充分地生长。
(3)用未参与建模的袋外数据去检验对应的CART树,通过袋外数据的预测误差确定最佳决策树数量。
(4)利用建好的模型去预测测试集中的新数据,将所有CART树的预测结果平均值作为最终的预测结果。
RF模型建模流程图如
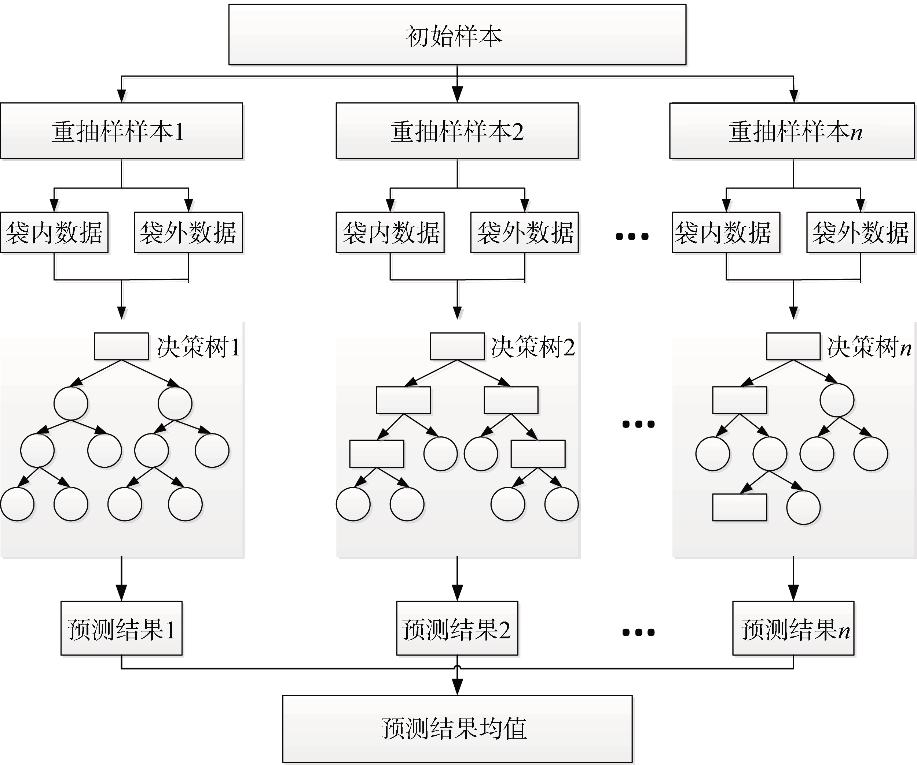
图1 随机森林建模流程
实验通过利用如
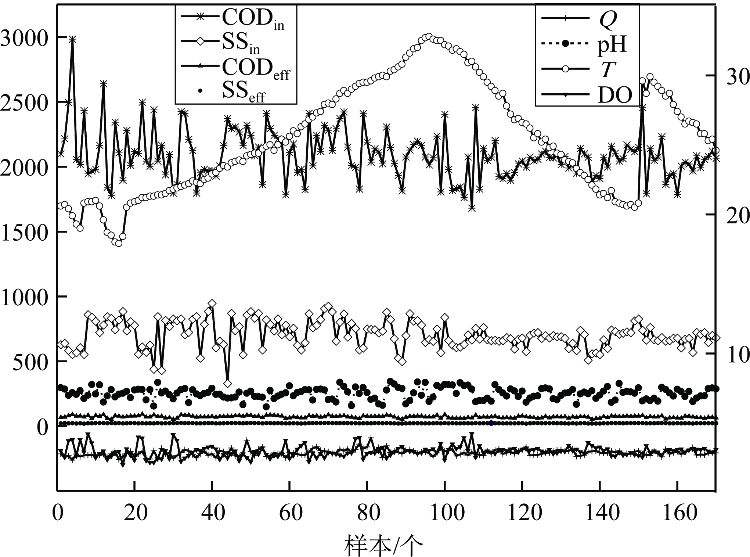
图2 造纸废水处理过程数据
图中左边纵坐标表示CODin(mg/L)、SSin(mg/L)、CODeff(mg/L)和SSeff(mg/L);右边纵坐标表示Q(1
建模的主要函数为R语言中randomForest包中的randomForest函数。该函数中需要寻优的主要参数有2个,分别为决策树的棵数n_tree与树节点的变量个数m_try,其默认参数分别为n_tree=500,m_try=M/3(M为变量总个数)。参数的可调范围分别为n_tree∈[1,500],m_try∈[1,M]。考虑到较少的决策树使得模型效果无法完全发挥,模型错误率偏高,而较多的决策树则会提升模型复杂程度,使得模型训练与预测速度下降,并有可能出现轻微的过拟合现象。本课题通过调用R语言自带函数plot对模型错误率与决策树数量的关系可视化处理如
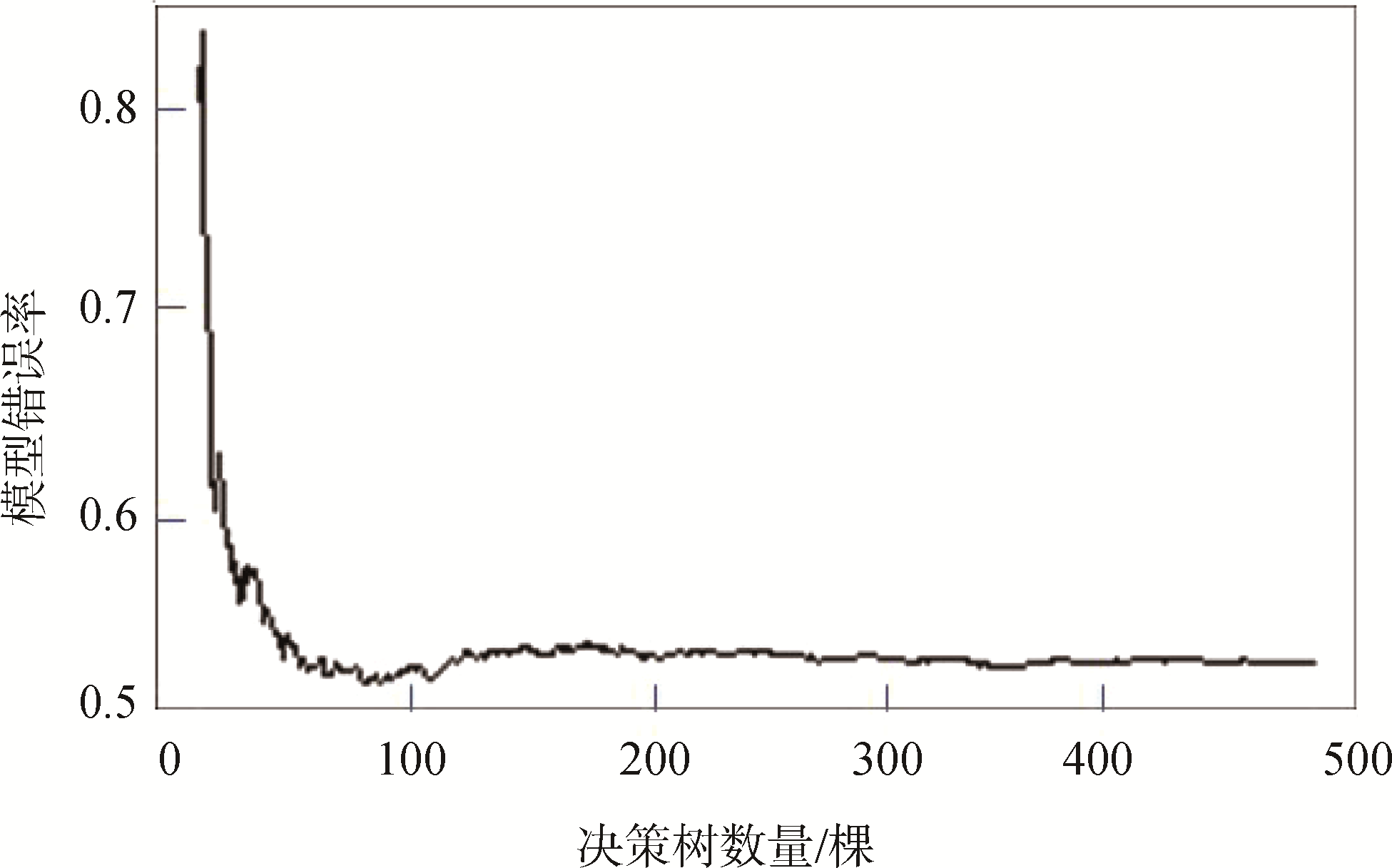
图3 模型错误率与决策树数量关系图
建立3种对比模型前先需要将数据标准化处理,之后用前120组数据进行建模,后50组数据用来检验预测效果。SVR模型所利用的主要程序包为R语言中的rminer包,其中模型参数选用SVM。ANN模型建模所利用的程序包主要为AMORE包。通过大量的实验选出构建模型的最佳参数为:模型的网络总层数为3层,包含1个输入层、1个隐含层和1个输出层,其中输入层节点数为6,隐含层节点数为2,输出层节点数为1,隐含层采用tansig激活函数,输出层采用purelin激活函数。根据赤池信息量准则,PLS模型最终选择了3个与预测变量相关度最大的自变量作为输入变量,分别为CODin、SSin、DO。
经过模型的建立及后续的优化后,
| 模型 | CODeff | SSeff | |||||
|---|---|---|---|---|---|---|---|
| RMSE | MAPE/% | r | RMSE | MAPE/% | r | ||
| ANN | 训练集 | 4.4769 | 4.3996 | 0.8528 | 0.6942 | 2.3299 | 0.8084 |
| 测试集 | 5.2566 | 6.5094 | 0.6936 | 0.8431 | 2.7962 | 0.6538 | |
| SVR | 训练集 | 4.3545 | 4.3149 | 0.8521 | 0.5726 | 2.1600 | 0.8757 |
| 测试集 | 5.0413 | 5.6905 | 0.7183 | 0.8123 | 2.9403 | 0.6882 | |
| PLS | 训练集 | 4.7541 | 5.2146 | 0.8264 | 0.7897 | 2.8166 | 0.7555 |
| 测试集 | 4.8293 | 5.6979 | 0.7305 | 0.8091 | 2.8899 | 0.7408 | |
| RF | 训练集 | 2.3473 | 2.4533 | 0.9656 | 0.3745 | 1.3577 | 0.9648 |
| 测试集 | 4.2471 | 5.2606 | 0.7954 | 0.6687 | 2.0633 | 0.8551 | |
总体而言,RF模型在预测精准度方面都优于其他3种常用的回归预测模型,
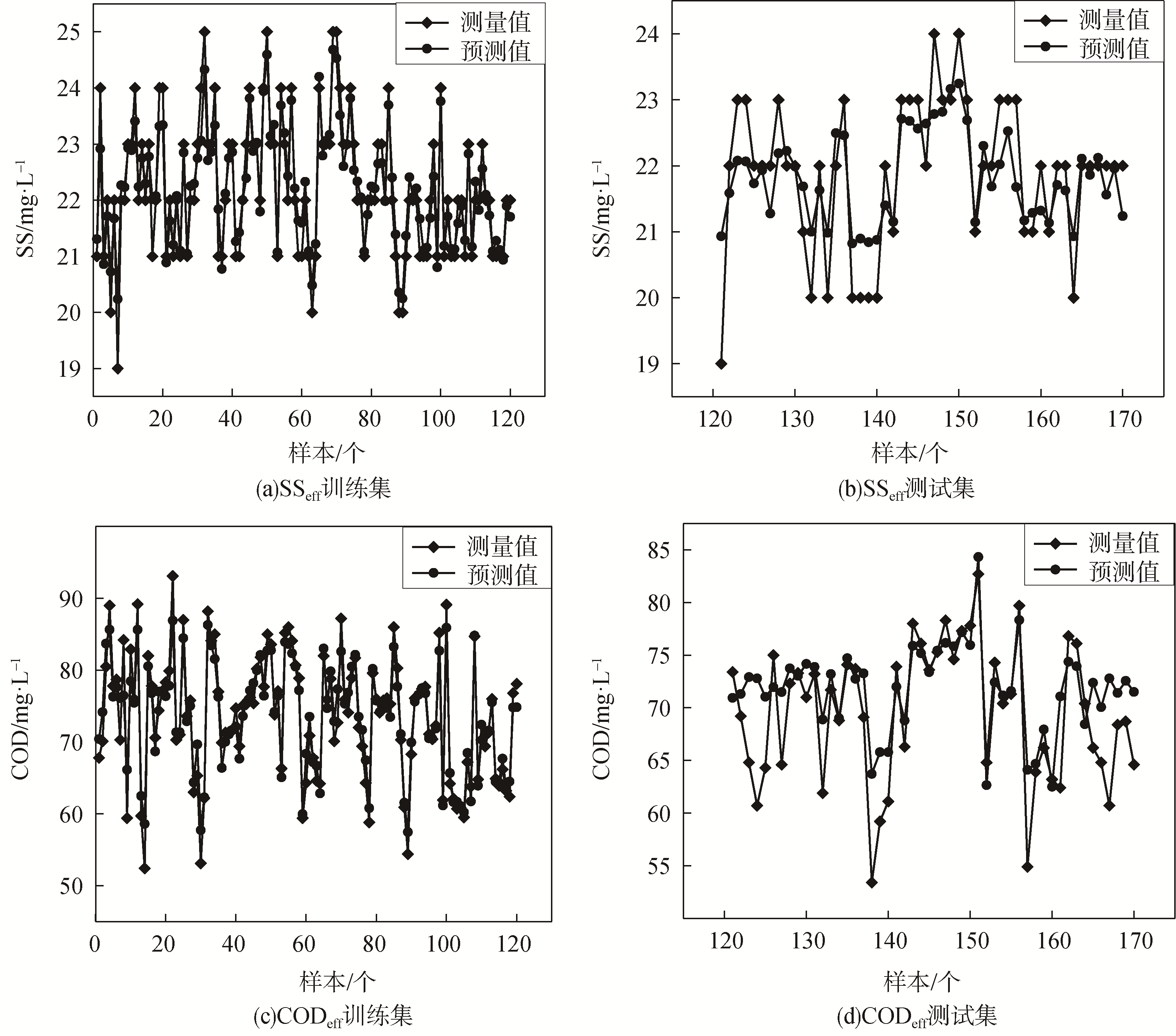
图4 RF模型对SSeff和CODeff的预测结果
RF模型比其他3种模型预测效果好的主要原因在于RF模型的泛化能力更强,实验中所用到的RF模型包含200棵决策树,而每棵决策树的生长只利用了训练集中的一部分样本,同时只抽取样本属性中的部分属性。采用该方法极大地提高了决策树的多样性,弱化了各棵决策树的相关性。同时,RF模型需要调整的主要参数只有2个,即决策树的棵数与树节点预选的变量个数,且易于寻找最优参数。
相比之下,虽然ANN模型具有较强的非线性拟合能力,但在构建模型的过程中,所要考虑的参数种类过多,在初始值、动量因子、网络结构、节点个数等参数方面没有统一规范的寻优方法,尝试通过原理推导或实验结果比较进行寻找最优参数是一件耗时费力的工作,往往会出现训练集预测效果较好,但测试集预测效果时好时坏的情况,容易出现过拟合现象,模型的泛化能力一般。SVR虽然相比于ANN过拟合现象得到了弱化,但根据实验预测效果来看并不是很理想,想要进一步提升预测效果还需要在原始模型上增添优化函数。PLS模型预测效果虽然比ANN模型与SVR模型好,但其线性模型的本质限制了它进一步优化的空间,且实验结果证明PLS模型只适合选择3个自变量作为输入变量,并不能充分地利用收集到的数据所蕴含的信息。
ANN、SVR、PLS在进行预测前,也都需要对数据进行标准化处理,实验中统一用z-score方法标准化,目的就是为了在建模过程中让不同的自变量具有相同的尺度,对因变量的影响程度基本相同。RF模型与上述3种方法相比省去了这一步骤,因为每棵决策树的生成过程都是依次用到部分自变量,所以不同尺度的自变量之间互不影响。
本课题分别采用随机森林(RF)模型、偏最小二乘(PLS)模型、支持向量回归(SVR)模型与人工神经网络(ANN)模型对造纸废水中的CODeff与SSeff指标进行了回归预测。
3.1 通过与其他3种模型的预测结果比较得出:基于随机森林回归模型的预测效果最好,预测值与真实值之间不仅相关性更高,且误差更小,泛化能力更强。
3.2 随机森林回归模型相比其他3种模型,数据无需标准化处理,寻找最优参数时所要调整的参数较少且容易寻优,易于进一步的推广。
参考文献
Zhu Xue-feng,Li Yan,Huang Dao-ping . The Overview on Control and Optimization in Wastewater Treatment Processes[J]. Automation & Information Engineering,2009, 30(3): 7.
朱学峰,李 艳,黄道平 . 污水处理过程的控制与优化综述[J]. 自动化与信息工程, 2009, 30(3): 7.
WANG Lingsong,MA Pufan,YE Fengying,et al . Incipient Fault Detection in Papermaking Wastewater Treatment Processes[J]. China Pulp & Paper,2017, 36(8): 20.
王龄松,马璞璠,叶凤英,等 . 造纸废水处理过程微小故障检测方法研究[J]. 中国造纸, 2017, 36(8): 20.
Cao Peng-fei,Luo Xiong-lin . Modeling of Soft Sensor for Chemical Process[J]. CIESC Jorunal,2013, 64(3): 788.
曹鹏飞,罗雄麟 . 化工过程软测量建模方法研究进展[J]. 化工学报, 2013, 64(3): 788.
YANG Hao,MO Weilin,XIONG Zhixin,et al . Soft Sensor Modeling of Papermaking Effluent Treatment Processes Using RPLS[J]. China Pulp & Paper,2016, 35(10): 31.
杨 浩,莫卫林,熊智新,等 . 基于RPLS的造纸废水处理过程软测量建模[J]. 中国造纸, 2016, 35(10): 31.
Li Di,Tang Hui,Wan Jin-quan,et al . ANN-based Dynamic Modeling of Wastewater Treatment Process in Paper Making by Waste Paper[J]. Journal of South China University of Technology(Natural Science Edition),2005, 33(12): 42.
李 迪,唐 辉,万金泉,等 . 基于ANN的废纸造纸废水处理过程的动态建模[J]. 华南理工大学学报(自然科学版), 2005, 33(12): 42.
Zeng G M,Qin X S,He L,et al . A Neural Network Predictive Control System for Paper Mill Wastewater Treatment[J]. Engineering Applications of Artificial Intelligence, 2003, 16(2): 121.
Li Xiao-dong,Zeng Guang-ming,Huang Guo-he,et al . Chaos Neural Network (NN) Model for Short Term Predicting on the Influent Time Series of WWTP[J]. Acta Scientiae Circumstantiate,2006, 26(3): 416.
李晓东,曾光明,黄国和,等 . 城市污水量短时预测的混沌神经网络模型[J]. 环境科学学报, 2006, 26(3): 416.
Feng Rui,Zhang Hao-ran,Shao Hui-he . Soft Sensor Modeling Based on Support Vector Machine[J]. Information and Control,2002, 31(6): 567.
冯 瑞,张浩然,邵惠鹤 . 基于SVM的软测量建模[J]. 信息与控制, 2002, 31(6): 567.
Zhou Zhi-hua,Chen Shi-fu . Neural Network Ensemble[J]. Chinese Journal of Computers,2002, 25(1): 1.
周志华,陈世福 . 神经网络集成[J]. 计算机学报, 2002, 25(1): 1.
LIU Hongbin,LI Xiangyu,YANG Chong . Soft Sensor Modeling of Papermaking Waste Water Treatment Process Using PCA Dimensional Reduction Models[J]. Transactions of China Pulp and Paper,2018, 33(4): 50.
刘鸿斌,李祥宇,杨 冲 . 基于PCA降维模型的造纸废水处理过程软测量建模[J]. 中国造纸学报, 2018, 33(4): 50.
WANG Yao,XU Liang,YIN Wenzhi,et al . Soft Sensor Modeling of Papermaking Wastewater Treatment Processes Based on ANN and LSSVR[J]. Transactions of China Pulp and Paper,2017, 32(1): 50.
汪 瑶,徐 亮,殷文志,等 . 基于ANN和LSSVR的造纸废水处理过程软测量建模[J]. 中国造纸学报, 2017, 32(1): 50.
Zhang Shi-feng,Yang Cheng,Li Xiao-ming . Research on Sewage Treatment Based on LS_SVM[J]. Industrial Control Computer,2013, 26(4): 66.
张世峰,杨 成,李晓明 . 基于LSSVM逆系统在污水处理系统DO控制中的研究[J]. 工业控制计算机, 2013, 26(4): 66.
Li Xiangyu,Yang Chong,Song Liu,et al . Fault Diagnosis of Papermaking Wastewater Treatment Processes Based on Support Vector Machine[J]. Transactions of China Pulp and Paper,2018, 33(3): 55.
李祥宇,杨 冲,宋 留,等 . 基于支持向量机的造纸废水处理过程故障诊断[J]. 中国造纸学报, 2018, 33(3): 55.
Yang Da-lian,Liu Yi-lun,Zhou Wei,et al . Fatigue Life Prediction of Large-Span Samples Based on the Optimized SVR Model[J]. Journal of Northeastern University (Natural Science Edition),2015 (9): 1321.
杨大炼,刘义伦,周 维,等 . 基于优化 SVR 模型的大跨度样本疲劳寿命预测[J]. 东北大学学报(自然科学版), 2015(9): 1321.
Breiman L . Bagging predictors[J]. Machine Learning, 1996, 24(2): 123.
Cao Wen-zhe,Ying Jun,Chen Guang-fei,et al . Risk Prediction and Comparitive Research of Type 2 Diabetes Mellitus Complicated with Retinopathy based on Logistic Regression and Random Forest Algorithm[J]. China Medical Equipment,2016, 31(3): 33.
曹文哲,应 俊,陈广飞,等 . 基于Logistic回归和随机森林算法的2型糖尿病并发视网膜病变风险预测及对比研究[J]. 中国医疗设备, 2016, 31(3): 33.
Fang Kuang-nan,Wu Jian-bin,Zhu Jian-ping,et al . A Review of Technologies on Random Forests[J]. Statistics & Information Forum,2011, 26(3): 32.
方匡南,吴见彬,朱建平,等 . 随机森林方法研究综述[J]. 统计与信息论坛, 2011, 26(3): 32.
Wu Xiao-yu,He Jing-han,Zhang Pei,et al . Power System Short-term Load Forecasting Based on Improved Random Forest with Grey Relation Projection[J]. Automation of Electric Power Systems,2015, 39(12): 50.
吴潇雨,和敬涵,张 沛,等 . 基于灰色投影改进随机森林算法的电力系统短期负荷预测[J]. 电力系统自动化, 2015, 39(12): 50.
Dietterich T G . An Experimental Comparison of Three Methods for Constructing Ensembles of Decision Trees: Bagging, Boosting, and Randomization[J]. Machine Learning, 2000, 40(2): 139.
Liu Min,Lang Rong-ling,Cao Yong-bin . Number of trees in random forest[J]. Computer Engineering and Applications,2015(5): 126.
刘 敏,郎荣玲,曹永斌 . 随机森林中树的数量[J]. 计算机工程与应用, 2015(5): 126.
Chen Yun-ying,Wu Ji-qin,Xu Ke-jia . Using Gini-Index for Attribute Selection in Decision Trees[J]. Microcomputer Development,2004, 14(5): 66.
陈云樱,吴积钦,徐可佳 . 决策树中基于基尼指数的属性分裂方法[J]. 微机发展, 2004, 14(5): 66.
CPP